
IDA 기초
IDA에는 수많은 기능들이 존재
IDA는 정적 분석 + 동적 분석을 둘 다 할 수 있는 종합 리버싱 툴.
주요한 기능들 중 Freeware에서 지원하는 정적 분석 기능들을 위주로 소개
Index
자료형 재설정 및 calling convention 재설정
IDA 기능 사용 예시 (rename, 주석, 자료형 변경, 구조체 작성)
다운 링크
IDA 인터페이스 소개
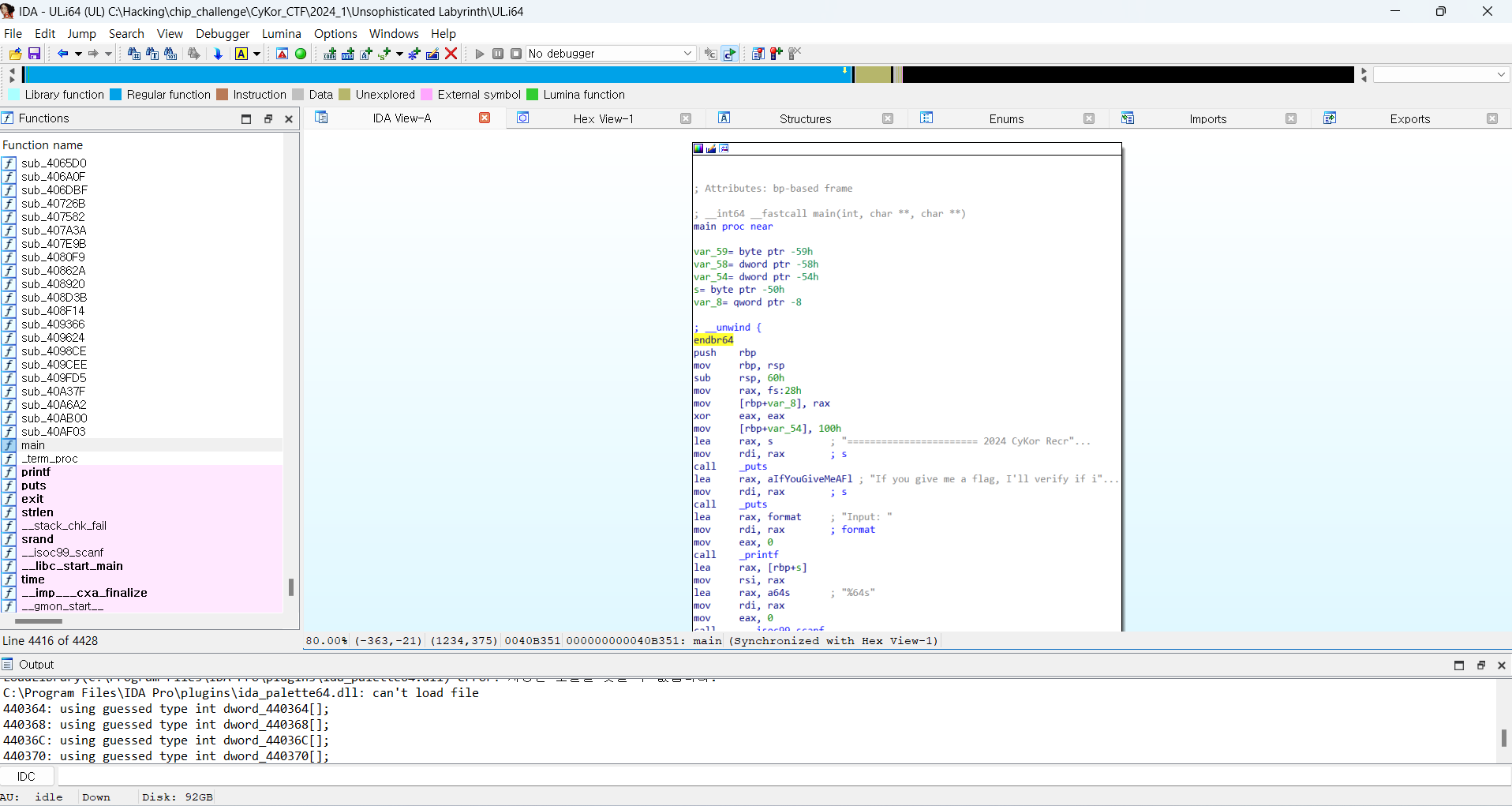
IDA에서 실행 파일을 열었을 때는 위와 같은 화면이 나옵니다.
function list
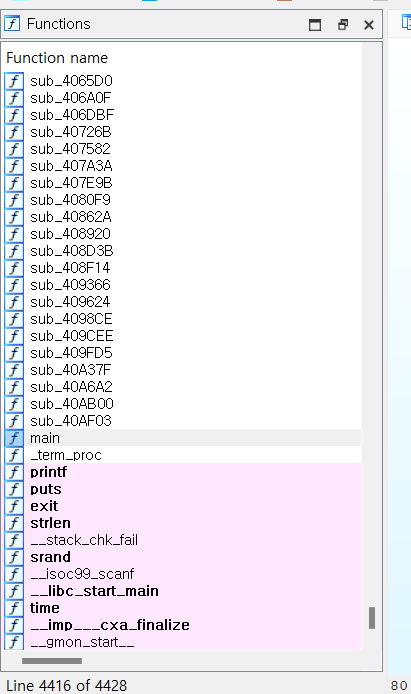
왼쪽에 위치한 조그마한 창에서 함수 list들을 확인할 수 있습니다.

흰색: 실행 파일 내부에 선언된 함수들입니다. 이름이 sub_408F14 이런 형식으로 되어 있는데, 함수의 이름이 지워진 상태입니다. 함수의 이름이 지워진 상태에서는 sub뒤에 붙은 16진수 값이 해당 함수가 존재하는 주소(가상주소)를 의미합니다. 함수의 이름이 지워지지 않았으면 선언된 함수 이름이 표기됩니다.
보라색: import 함수. 라이브러리에 있는 함수들을 의미합니다. 그렇기에 실행 파일 내부에 함수가 선언되어 있지 않으므로 함수 내부를 들여다볼 수 없습니다. 해당 라이브러리를 IDA에서 따로 열면 해당 함수를 볼 수 있는데, 일반적으로 라이브러리에 있는 함수들은 검색하면 다 나오기에 굳이 라이브러리를 찾아서 IDA로 열거나 하는 일은 거의 없습니다.

초록색: 실행파일의 실행 및 종료에 관여하는 함수들인 것으로 보입니다. start함수는 실행파일의 entry point입니다.
실행파일을 실행하면 운영체제(OS)가 해당 실행파일을 RAM에 로드한 뒤 entry point(start 함수)부터 실행합니다.
메인 인터페이스
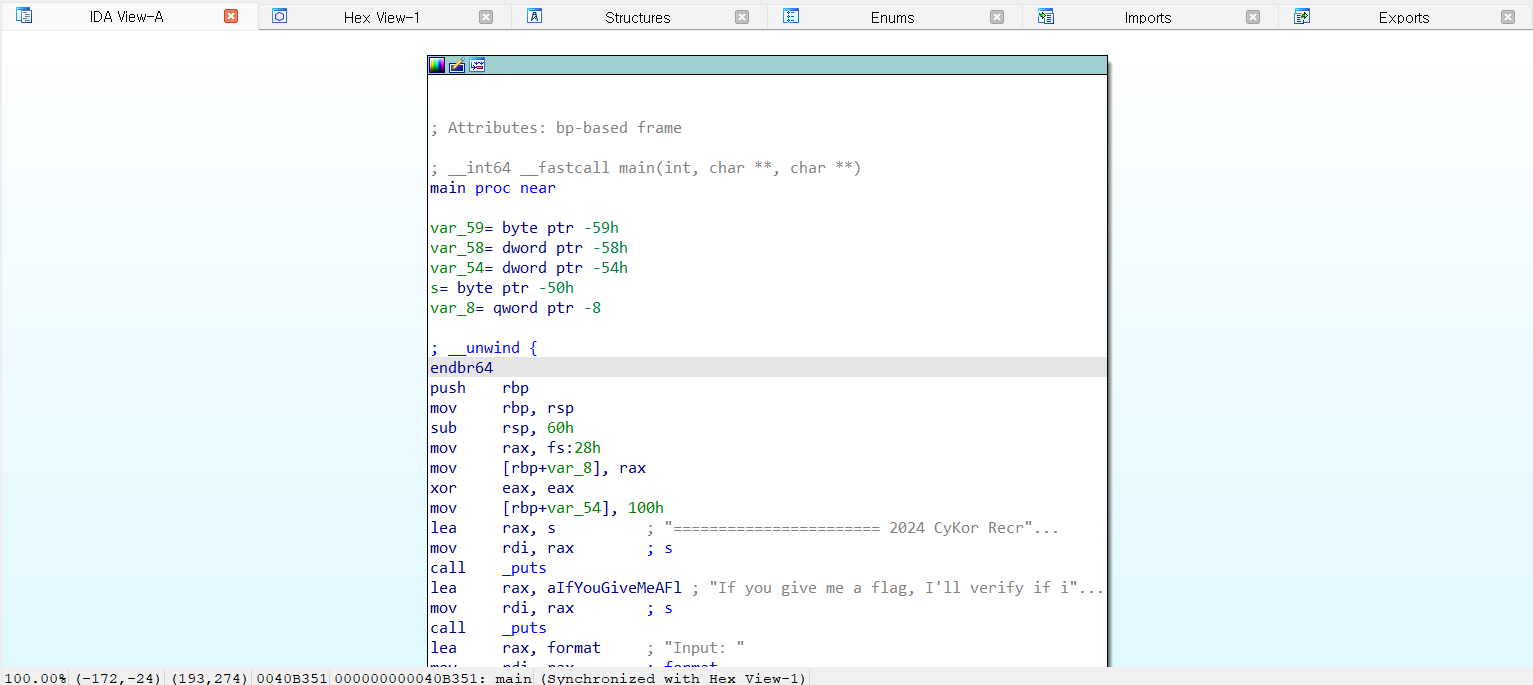
중간에 크게 보이는 화면이 있습니다.
여러 subview들로 이루어져 있는데, 지금 위의 캡쳐본에서는 IDA View-A, Hew View-1, Structures, Enums, Imports, Exports가 있습니다다.
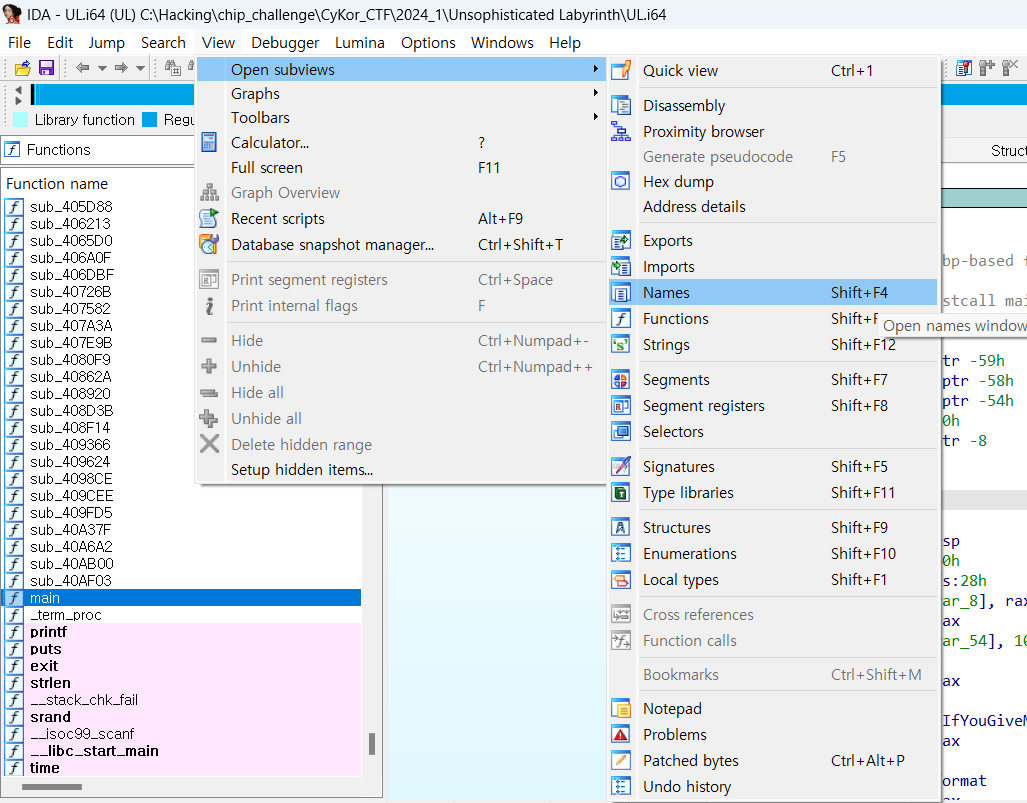
이렇게 View - Open subviews에 들어가면 이렇게 여러 subview들을 열 수 있습니다. 열면 일반적으로 메인 인터페이스 쪽에 열리게 되고, 드래그 하면 원하는 곳에 해당 subview를 갖다 놓을 수 있습니다. 참고로 위에서 설명한 함수 리스트도 Functions라는 subview입니다다.
subview 중에서 IDA view와 Pseudocode 를 가장 많이 보시게 될 예정
IDA view
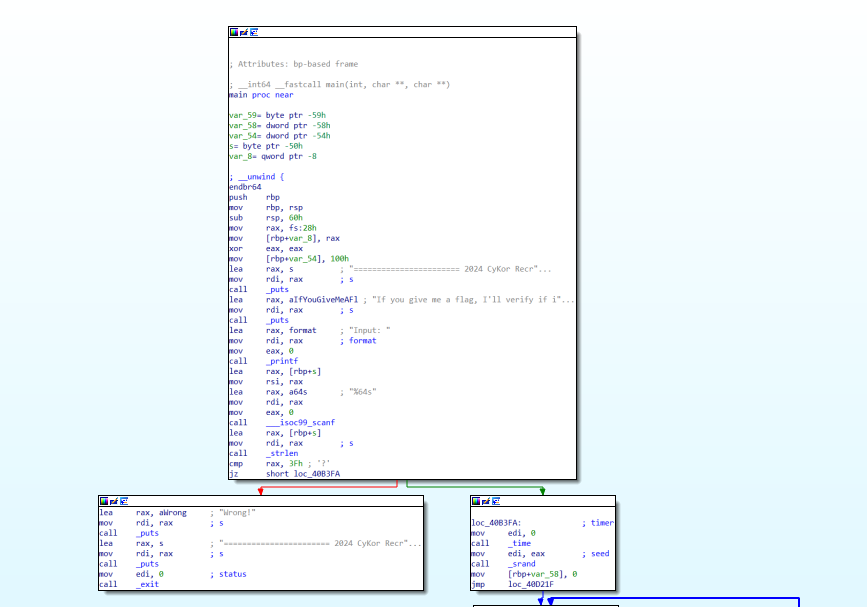
이렇게 함수의 어셈블리를 보여주는 창입니다. 현재는 graph view로 보여주고 있는데, graph view에서는 분기 등의 control flow(실행 흐름)을 시각적으로 보여줍니다. 여기서 스페이스 바 를 누르면 text view로 볼 수 있습니다.
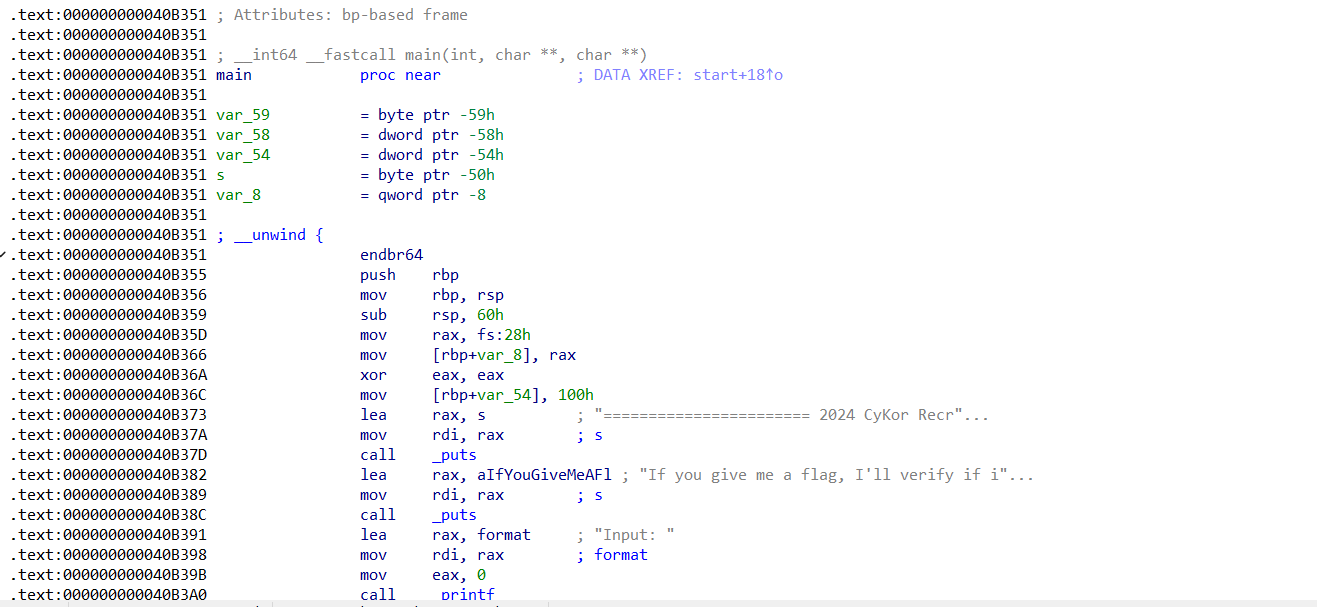
text view의 모습. gdb에서 디스어셈블 하면 text view의 형식으로 보여줍니다. graph view는 IDA가 control flow를 시각적으로 표현하기 위해 지원하는 좋은 기능 중 하나입니다.
graph view에서는 segment와 주소에 관련된 정보가 안보이는데, graph view로 해 놓은 상태에서 option - general 들어가서
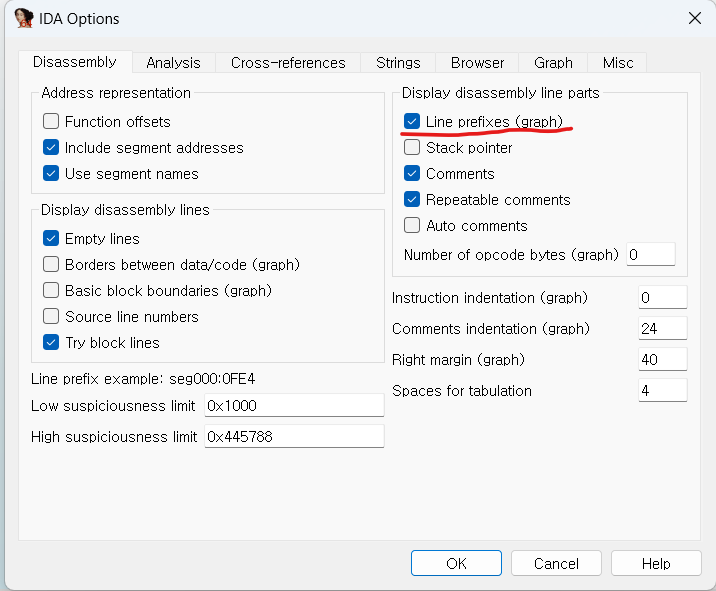
밑줄 쳐 놓은 부분 체크하시면
이런 식으로 볼 수 있지요
Pseudocode
IDA view에서 f5 를 누르면 보고 있는 함수를 디컴파일하여 Pseudocode subview를 보여줍니다.
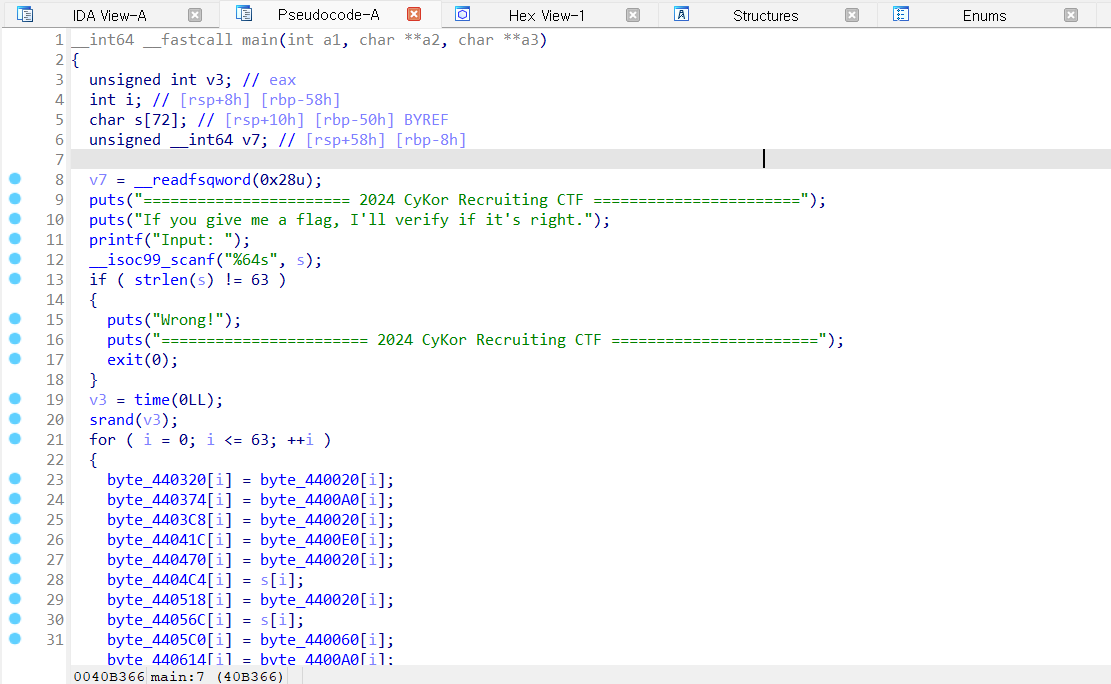
디컴파일은 기본적으로 C/C++로 디컴파일하며 함수 단위로 디컴파일합니다. (rust, go 등의 타 언어로 작성된 바이너리도 C/C++ 기반으로 디컴파일함)
기본적으로는 IDA가 디컴파일한 코드를 보면서 바이너리를 분석하면 되지만, 이 디컴파일된 코드를 100% 신뢰할 수는 없습니다. 그래서 Pseudo라는 키워드가 붙는 듯.
IDA view와 Pseudocode view 사이를 tab키로 왔다 갔다 할 수 있습니다. 그래서 디컴파일된 코드 중에서 특정 코드에 대응하는 어셈 코드를 보고 싶으면 그 코드에 커서를 위치시킨 채로(해당 코드를 클릭한 뒤) tab키 누르면 됩니다 (이 기능 굉장히 자주 사용함). 어셈에서 디컴코드로 가는 것도 동일하게 작동
IDA view, Functions, Pseudocode 창에서 변수명, 함수명 더블클릭 해봅시다. esc 를 누르면 더블클릭 이전으로 돌릴 수 있어요. 몇번 해보면 감이 오실 듯.
인터페이스 가꾸기
Function view는 왼쪽에 붙어있고 나머지 대부분의 subview들은 메인 화면에 큼지막하게 들어가게 되는데, 이게 고정된 것은 아닙니다. 원하는 대로 취향껏 바꿀 수 있습니다.
창 윗단을 클릭하여 드래그하면 이렇게 별개의 창으로 분리할 수 있습니다. 위 사진은 Pseudocode 창을 별개로 분리한 모습입니다.
저 분리된 창을 윗 부분을 보면 회색빛 줄이 있는데 해당 부분을 드래그하면 인터페이스의 여러 부분으로 다시 합칠 수 있습니다.
해당 기능을 이용하여 IDA View와 Pseudocode를 동시에 띄우거나 창 위치를 다른 곳으로 옮기거나 인터페이스를 마음대로 가꿀 수 있습니다.
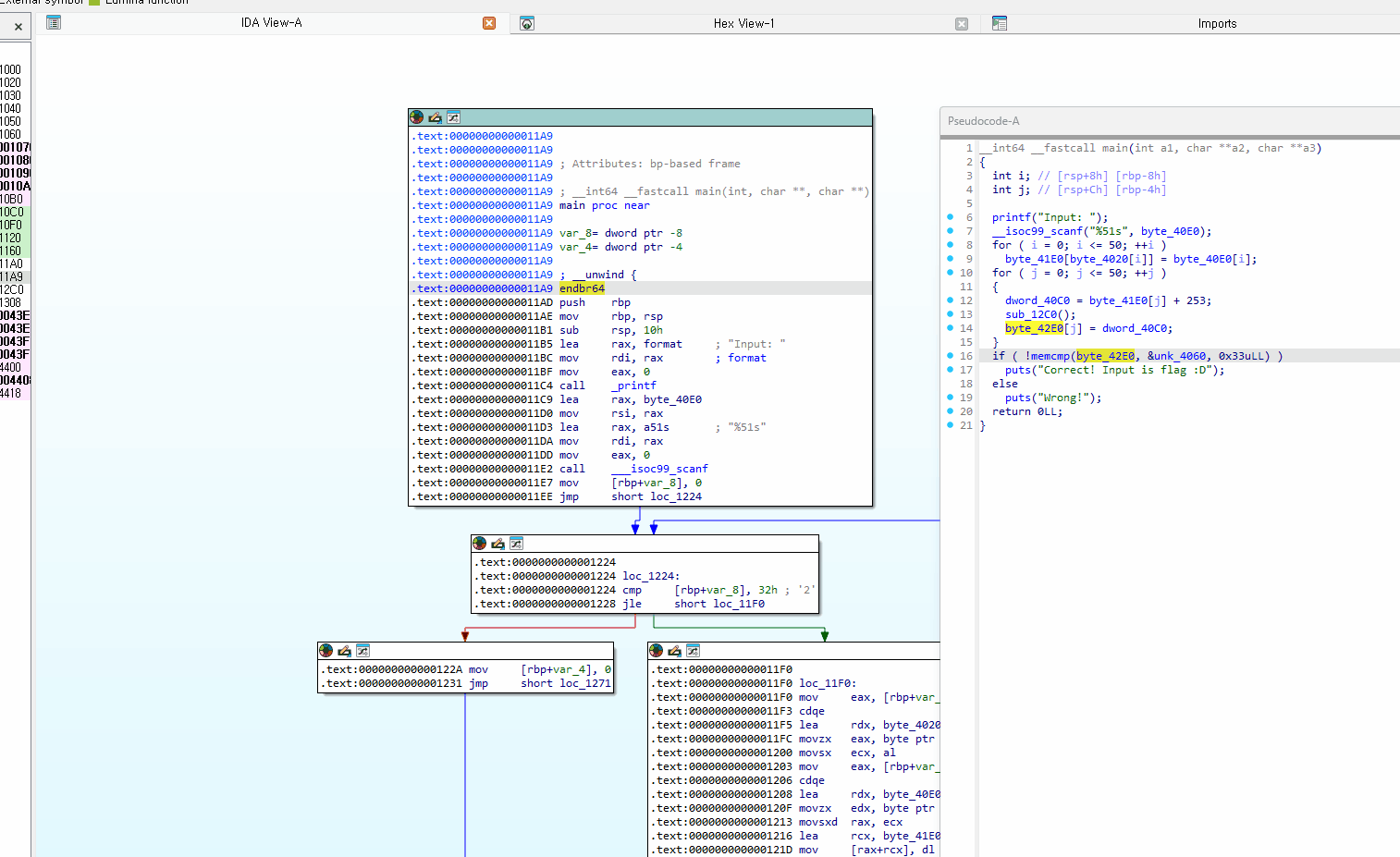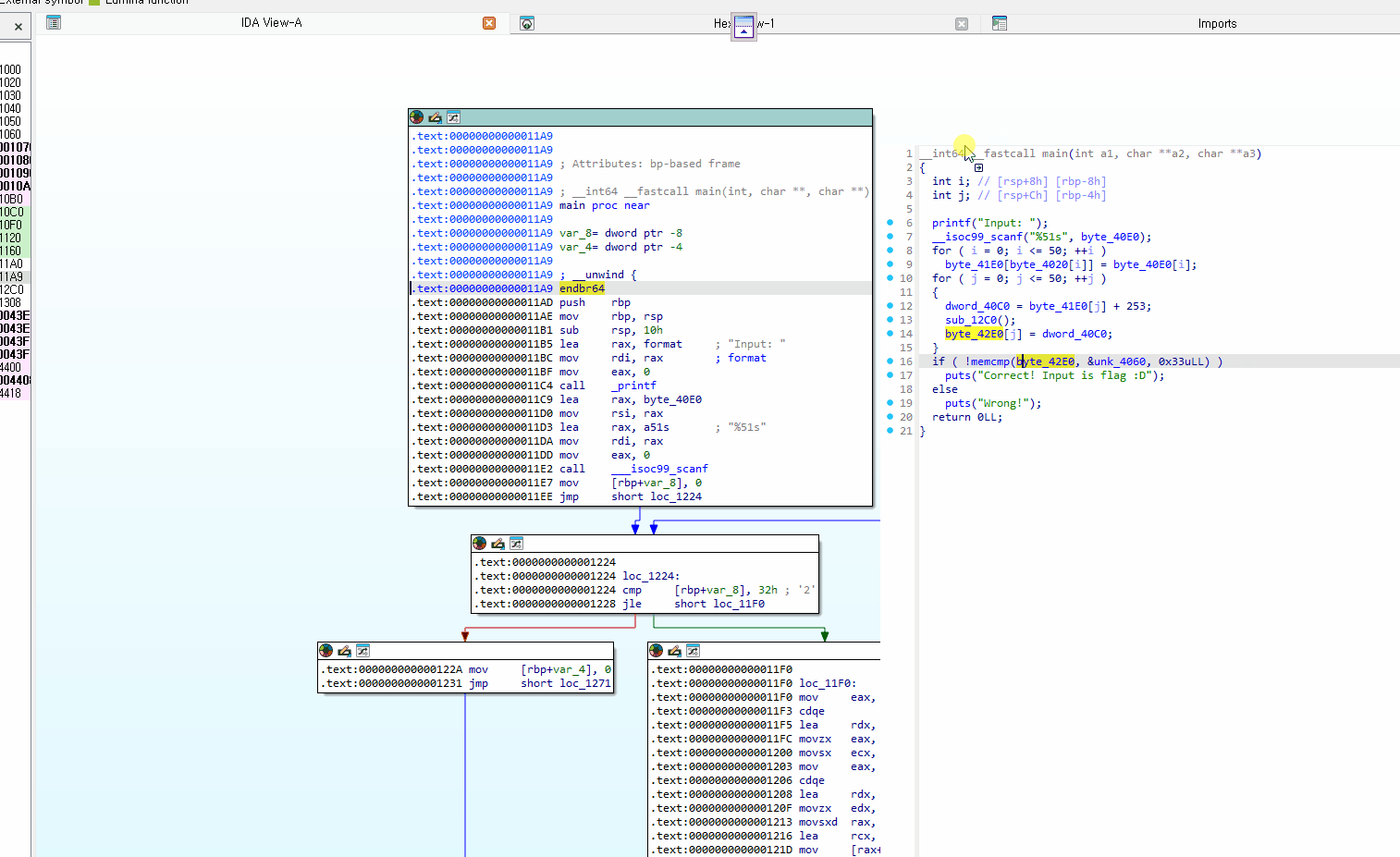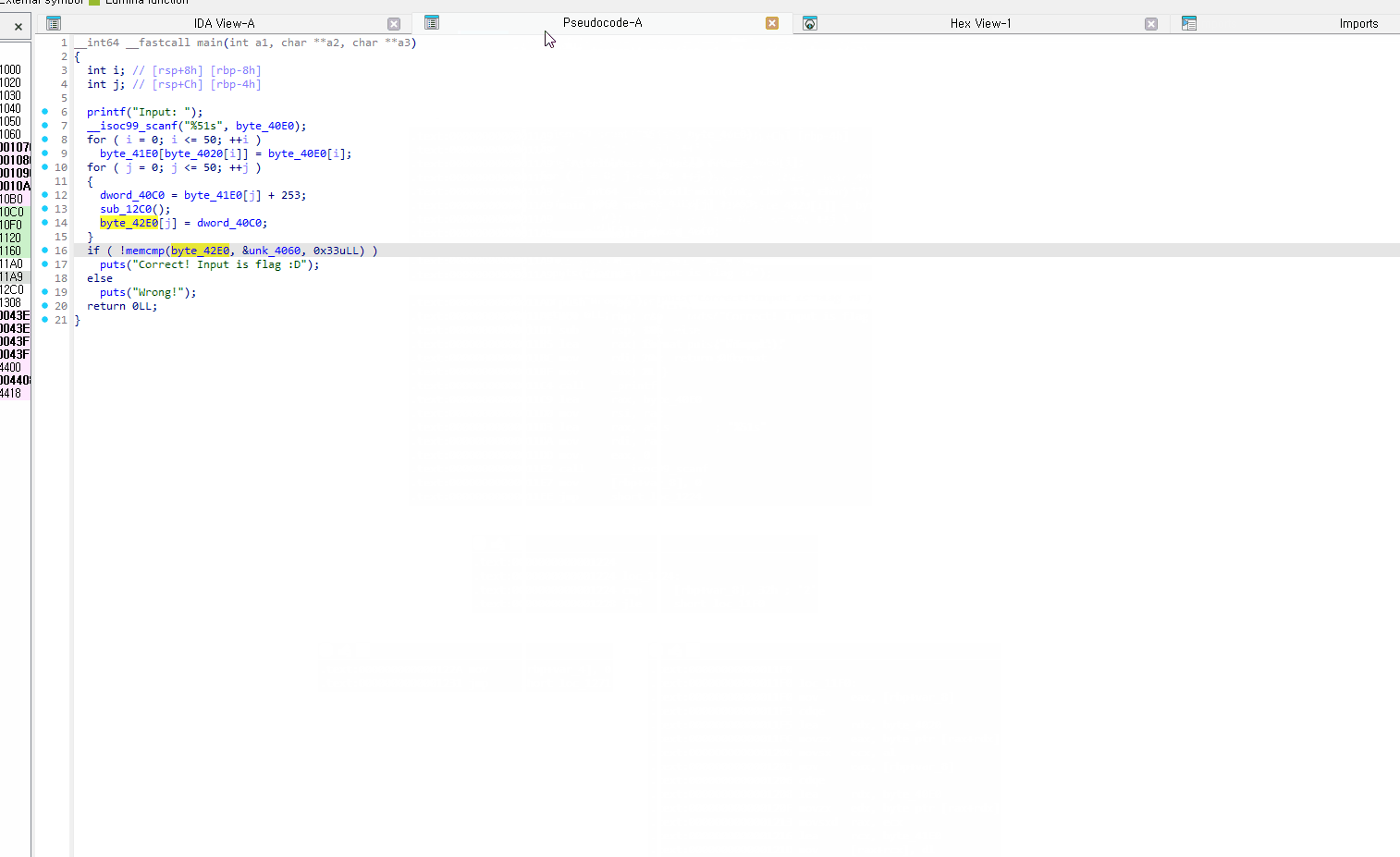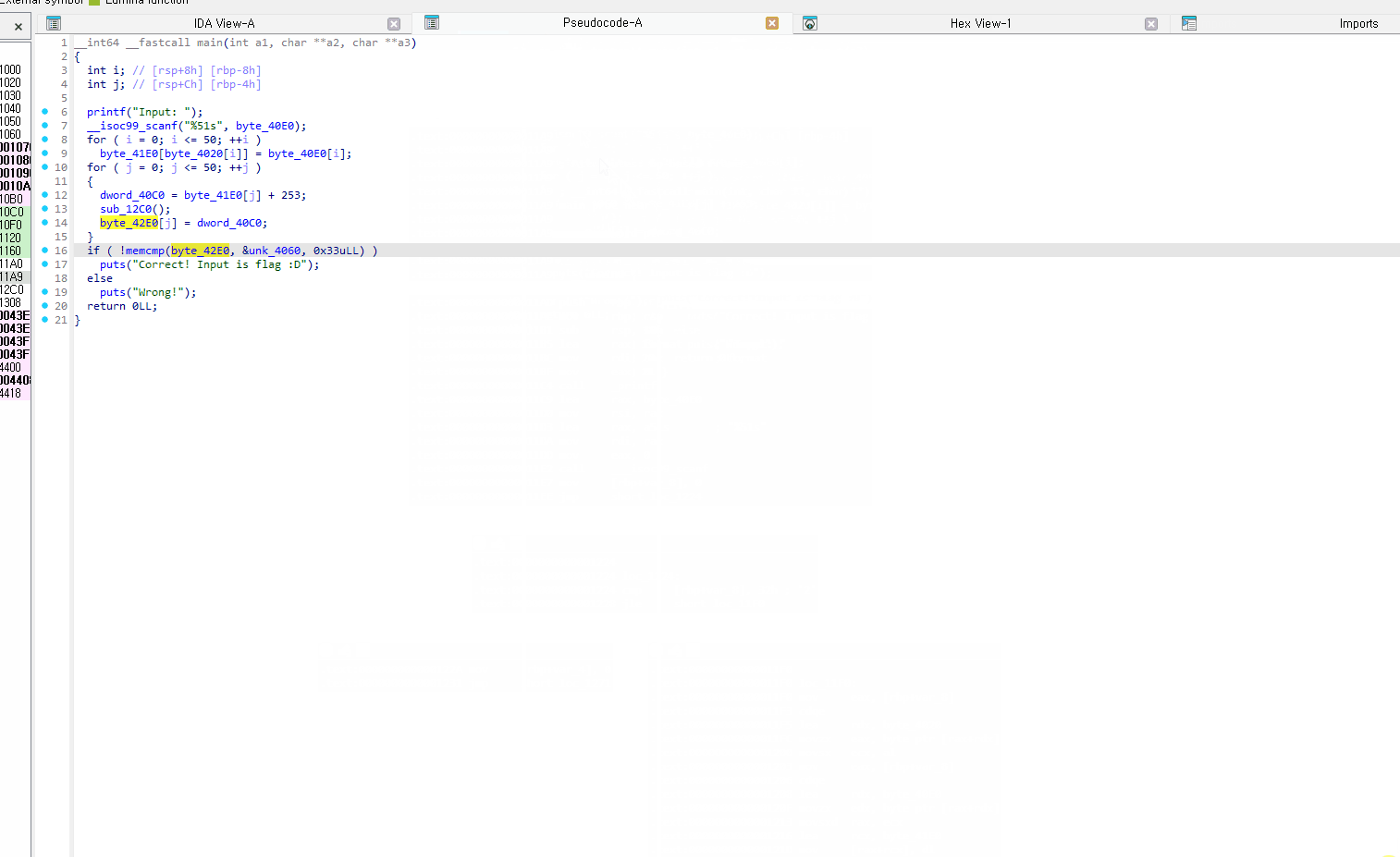
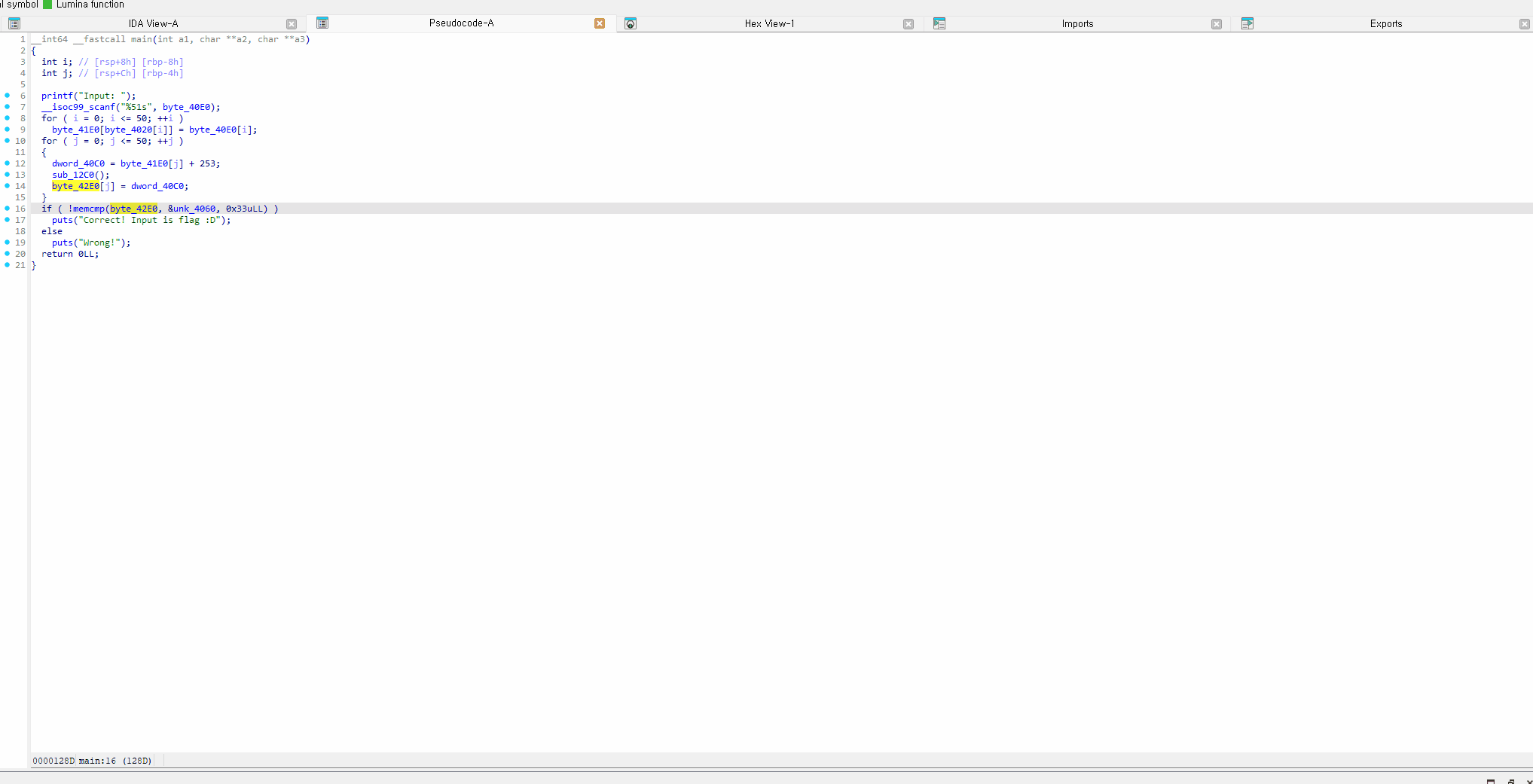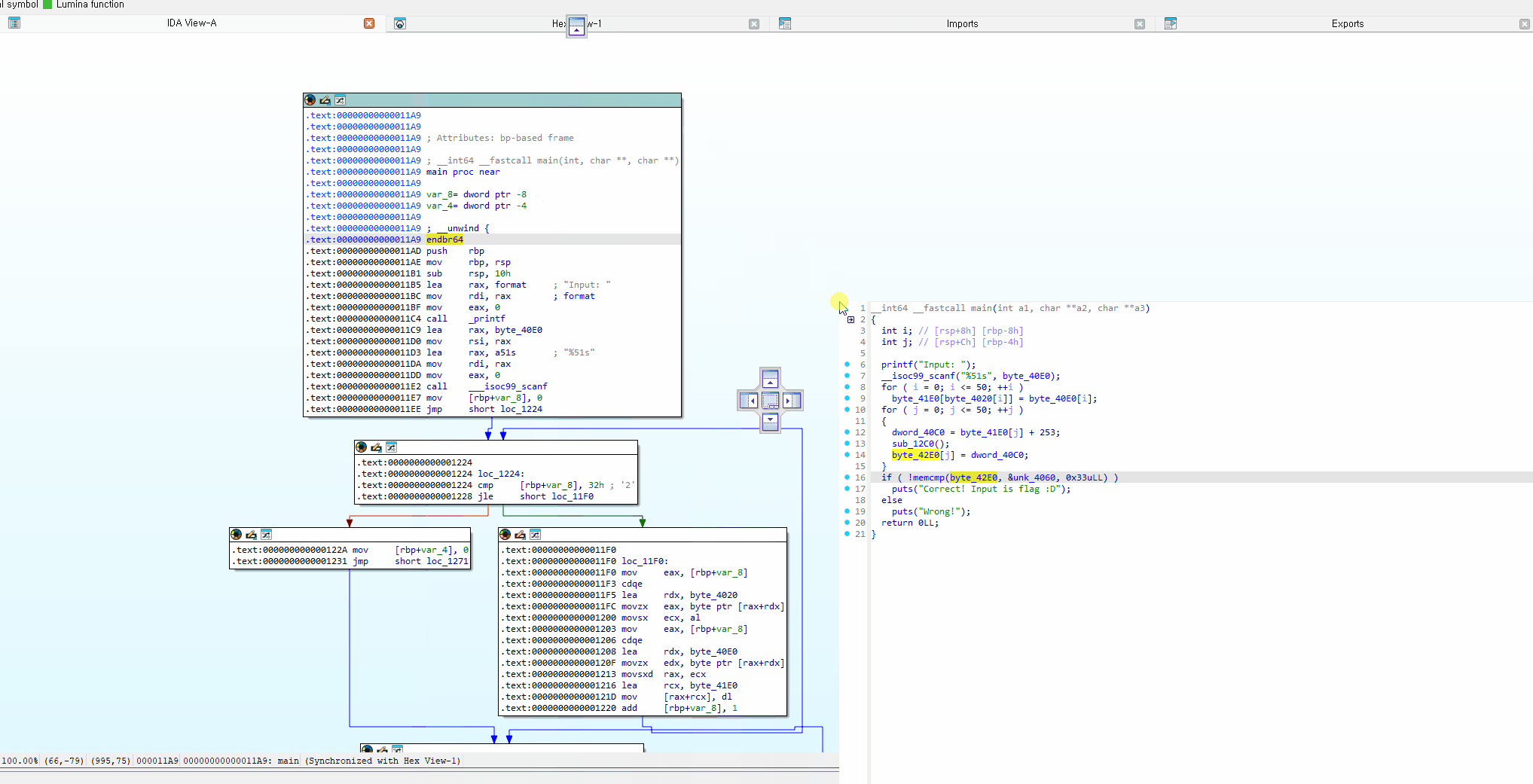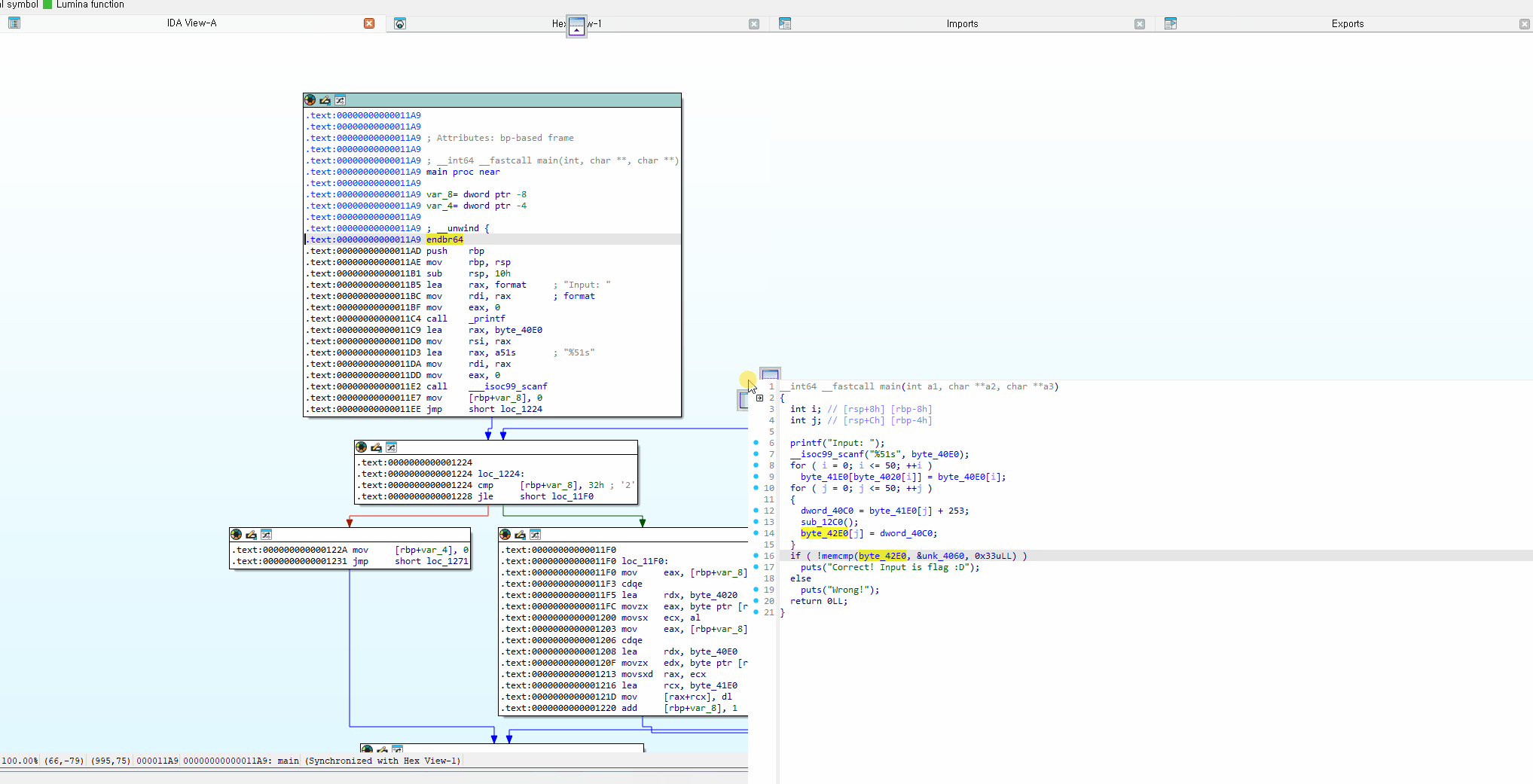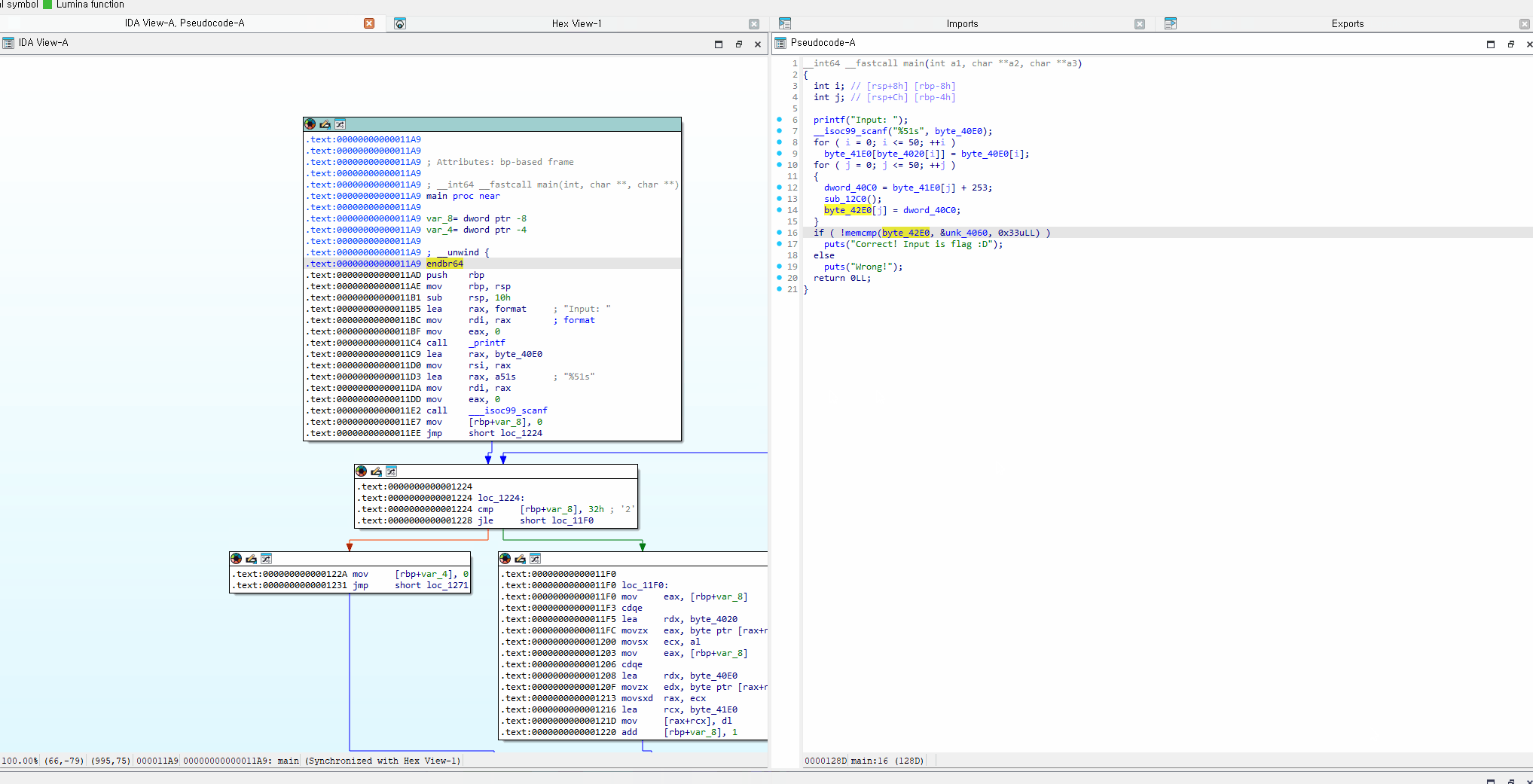
주요 기능 소개
rename
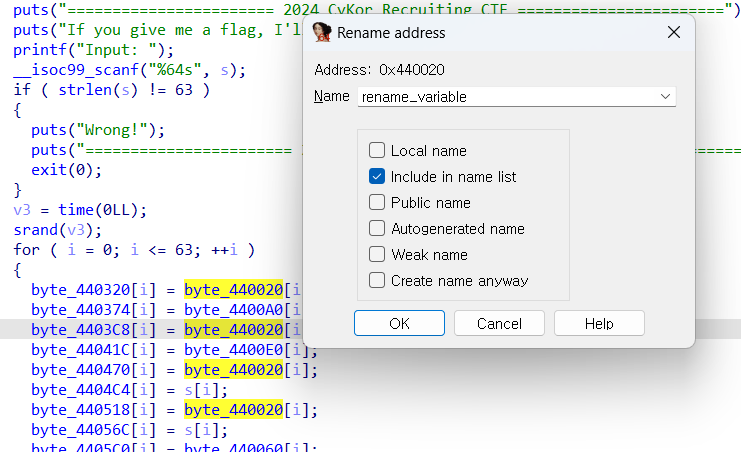
rename하고 싶은 변수 or 함수를 클릭한 상태로 n 을 누르면 rename할 수 있음
xref (cross reference)
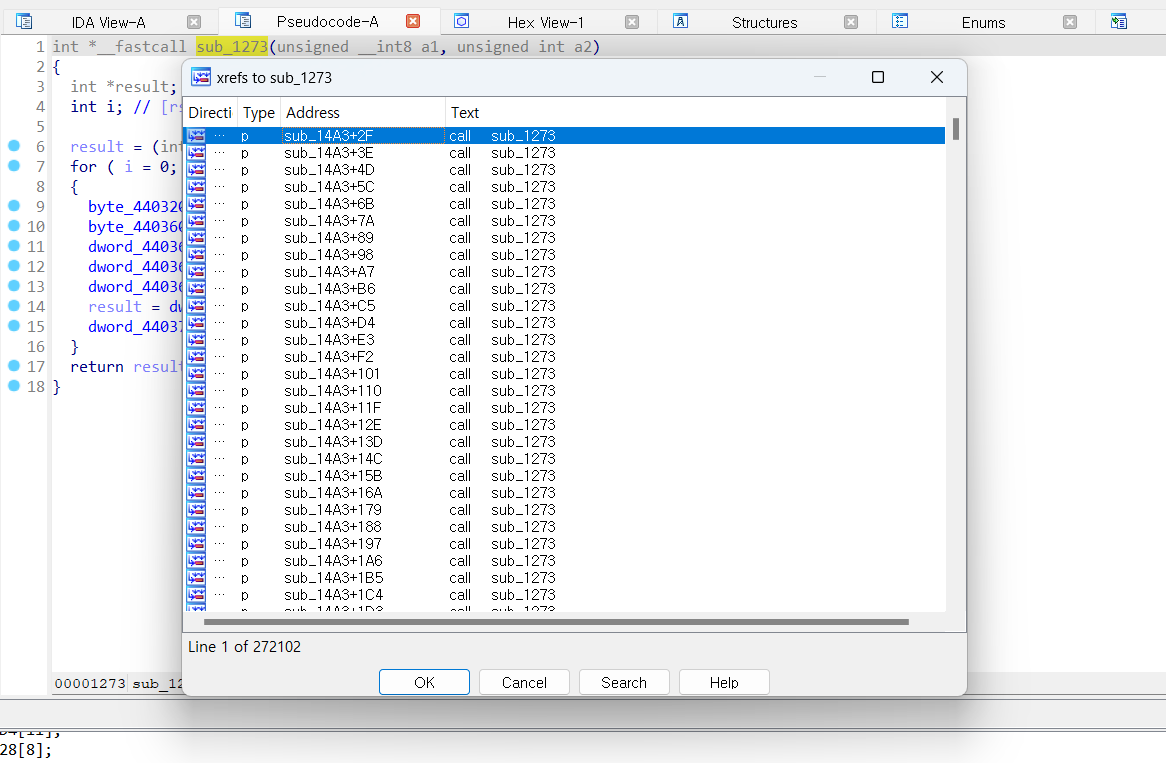
변수 or 함수를 선택한 채로 x를 누르면 xref list를 볼 수 있습니다. xref list는 해당 함수 or 변수를 참조한 지점을 의미. 더블클릭하면 해당 지점을 볼 수 있습니다.
위 캡쳐본의 sub_1273 는 엄청나게 많은 xref list가 나오는데, 하나만 예를 들어서 해당 리스트의 첫번째를 해석해보면 sub_14A3+2F가 sub_14A3 함수의 0x2F 위치에 있는 코드에서 call sub_1273 이라는 코드로 sub_1273 을 참조했다는 의미입니다.
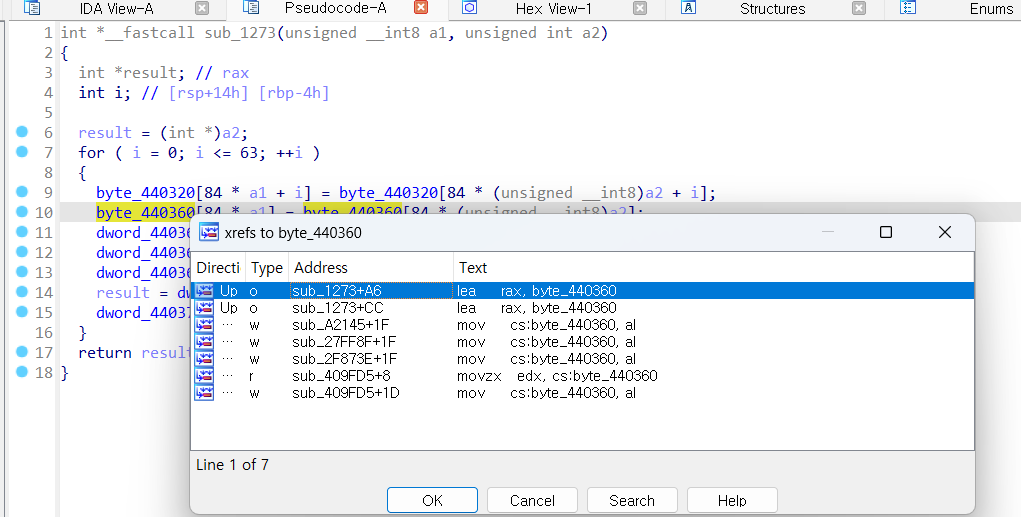
변수의 경우에는 이런 식으로 표현됩니다.
type이 3개가 있는데
w , r 는 각각 쓰기, 읽기
o 는 헷갈릴 수 있는데 이는 변수를 참조하는 것이 아닌 변수의 주소를 참조하는 곳이다.
지금 배열 byte_440360에 대한 xref list를 보고 있는 것인데
byte_440360[0] = value 는 w type
value = byte_440360[0] 은 r type
addr = 0x440360 or addr = byte_440360 은 o type이 되시겠다.
배열 변수 명이 해당 배열의 주소를 의미하는 것은 다들 아시죠??
비슷하게 배열이 아닌 단일 변수의 경우에는
addr = &variable 의 경우 o type이 될 수 있겠죠
이번 과제에서는 바이너리 사이즈가 다 작아서 xref 기능이 크게 유용하지는 않은데, 바이너리 사이즈가 조금만 커지면 굉장히 유용한 기능이 됩니다.
Name subview
ctrl+L 혹은 상단 subview 메뉴에서 찾을 수 있습니다.
여기서 ctrl+F 를 누르면 검색도 가능
Name은 IDA에서만 사용하는 용어인데, 함수명, 변수명 등을 찾을 수 있습니다. 일반적인 용어로 설명하면 Symbol 관련 정보를 검색할 수 있습니다. 여기서도 더블클릭하면 해당 변수 함수로 이동할 수 있습니다.
String Subview
shirt+f12 혹은 상단 subview 메뉴에서 찾을 수 있습니다.
바이너리에 존재하는 문자열들을 볼 수 있습니다. Ctrl+f를 이용하여 검색도 가능합니다.
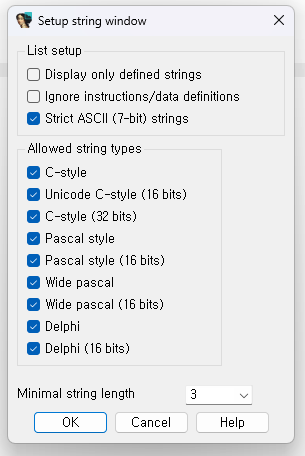
string subview 아무 공간에서 우클릭 - setup을 들어가면 string subview에 관한 설정을 수행할 수 있습니다. 문자열의 경우에는 여러 가지 인코딩 방식이 있기 때문에, 원하는 string type을 설정할 수 있습니다. 개인적으로는 그냥 다 켜 놓는 편입니다.
Minimal string length를 설정할 수 있습니다. 너무 길게 설정하면 유의미한 문자열들이 생략될 가능성이 있고, 너무 짧게 설정하면 string이 아닌 data가 string으로 잡힐 확률이 올라가서 무의미한 string들이 많아지게 되어서 적당한 길이 설정이 필요합니다. 3~5정도가 적당하다고 생각합니다.
주석 달기
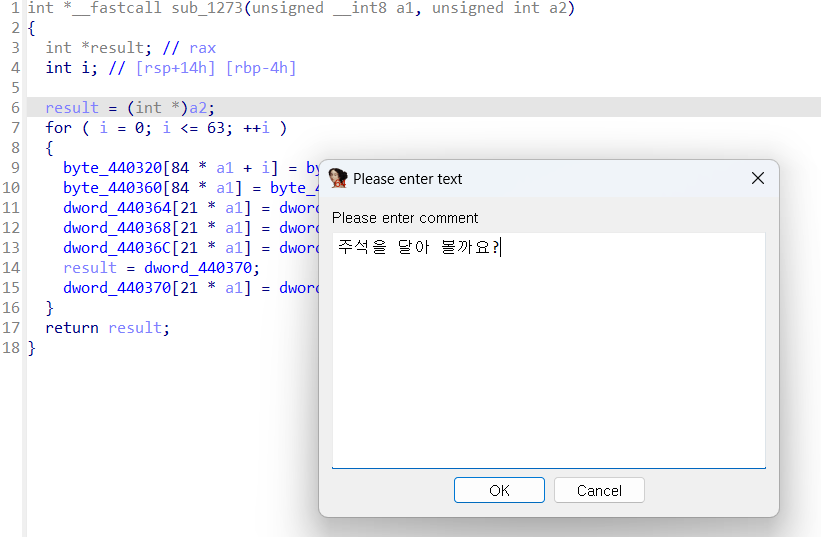
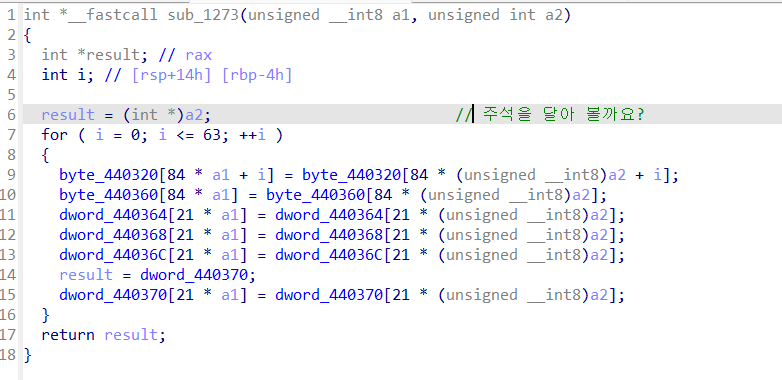
pseudocode 창에서 C 코드에 주석을 달고 싶으면 주석 달고 싶은 line에 클릭 뒤 / 버튼으로 주석을 달 수 있습니다.
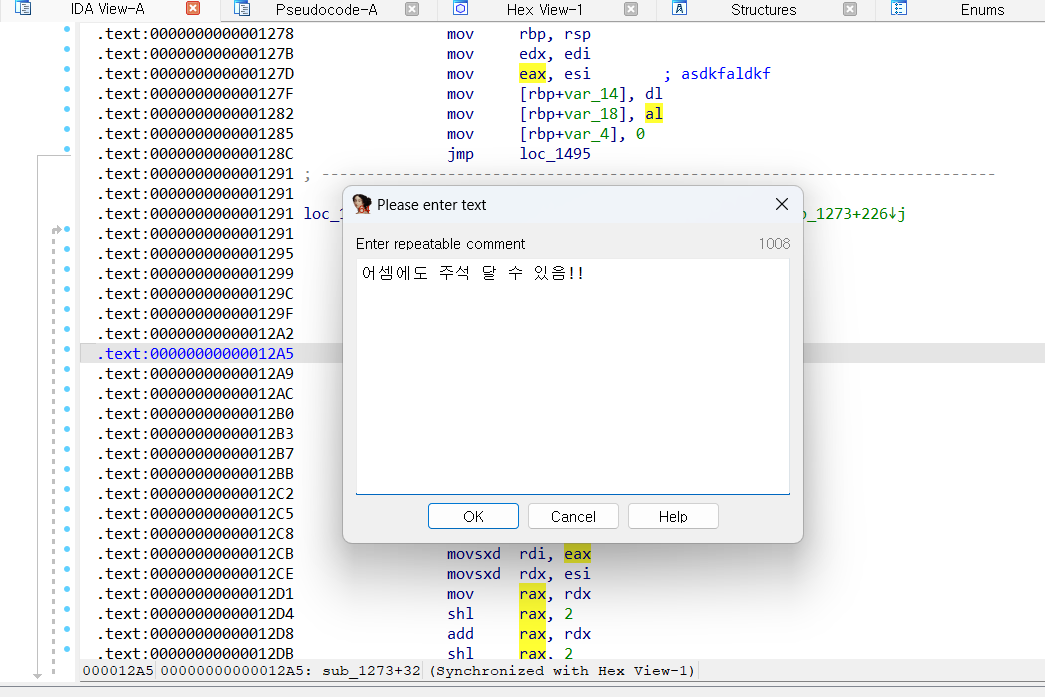

어셈에도 주석을 달 수 있는데 이 때는 ; 버튼으로 주석을 달 수 있습니다.
주석은 리버싱 할 때 도움이 굉장히 많이 되는 기능이기에 애용하는 습관을 기릅시다.
export 기능

데이터 영역에 있는 데이터들을 복사하고 싶은 경우가 자주 있을 거에요.
저걸 그냥 드래그 해서 복사하면
.data:0000000000440020 byte_440020 db 13h, 0Fh, 10h, 0Ch, 18h, 38h, 17h, 0Bh, 6, 5, 14h, 0Ch
.data:0000000000440020 ; DATA XREF: main+CB↑o
.data:0000000000440020 ; main+109↑o ...
.data:0000000000440020 db 10h, 9, 3, 6, 1, 34h, 3Ah, 2Ch, 16h, 4, 6, 24h, 36h
.data:0000000000440020 db 2Eh, 37h, 7, 12h, 20h, 7, 25h, 2Fh, 18h, 31h, 8, 10h
.data:0000000000440020 db 8, 13h, 16h, 0Eh, 27h, 22h, 1Eh, 30h, 25h, 24h, 32h
.data:0000000000440020 db 1Ah, 2 dup(1Eh), 30h, 22h, 24h, 14h, 18h, 12h, 0Ch
.data:0000000000440020 db 1Fh, 24h, 2Ch, 27h, 0Ah, 1Ch
이런 식으로 되는데… 이건 여러분들이 원하는 형태가 아닐 겁니다.
드래그 한 상태로 shift+e 를 눌러보면
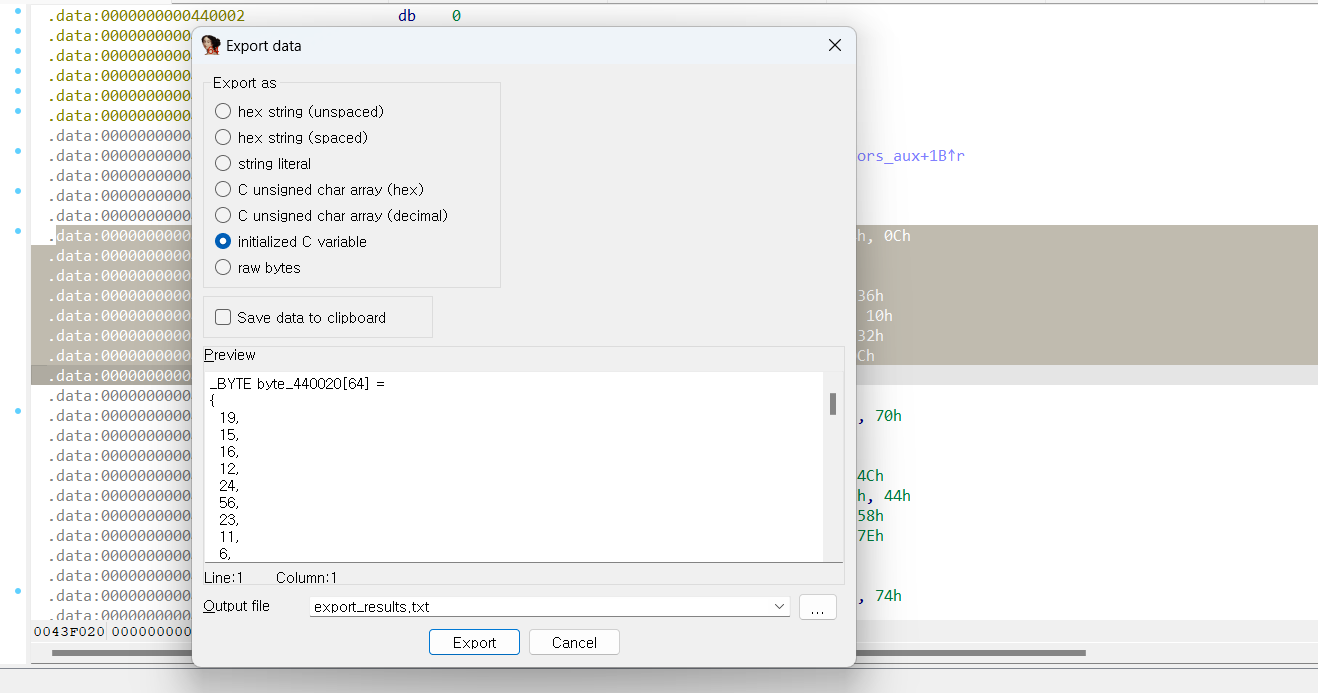
이런 식으로 원하는 형태로 export할 수 있습니다. 저 결과를 파일 형태로 저장도 가능하고 preview 창 클릭하고 ctrl+a 를 누른 채로 복사하면 복사도 가능합니다(다만 preview에 다 못 담을 정도로 데이터가 많은 경우는 이 방법이 통하지 않으니 이런 경우는 그냥 export를 눌러서 해당 값이 복사된 파일을 생성하도록 합시다). 주로 사용하는 형태는 initialized C variable 혹은 C unsigned char array 형식으로 export하는 경우가 많습니다(사실 복사하고 싶은 배열의 자료형에 따르면 됩니다).
나중에 IDA pro 버전을 사용하게 되면 plugin들을 다운 받아서 기능들을 확장시킬 수 있는데, lazyIDA plugin을 다운 받으면 python array, C/C++ array 등의 형태로 바로 복사가 가능합니다.
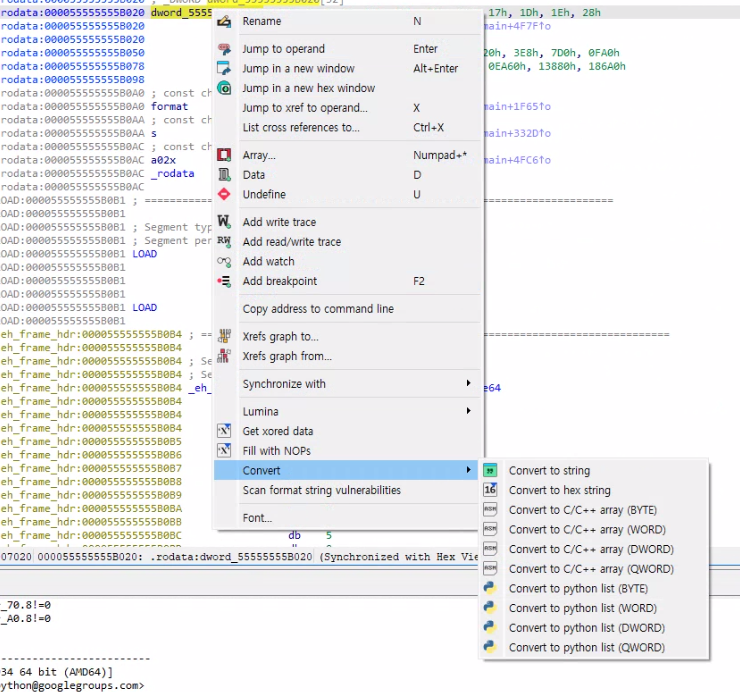
복사 결과
[0x00000002, 0x00000003, 0x00000005, 0x00000007, 0x0000000B, 0x0000000D, 0x00000011, 0x00000013, 0x00000017, 0x0000001D, 0x0000001E, 0x00000028, 0x0000003C, 0x00000050, 0x00000064, 0x000000C8, 0x00000190, 0x00000258, 0x00000320, 0x000003E8, 0x000007D0, 0x00000FA0, 0x00001770, 0x00001F40, 0x00002710, 0x00004E20, 0x00009C40, 0x0000EA60, 0x00013880, 0x000186A0, 0x00030D40, 0x0007A120]
매우 매우 편리함.
ImageBase 수정
이 기능은 gdb 실습해보면 그 필요성을 실감할 수 있습니다.
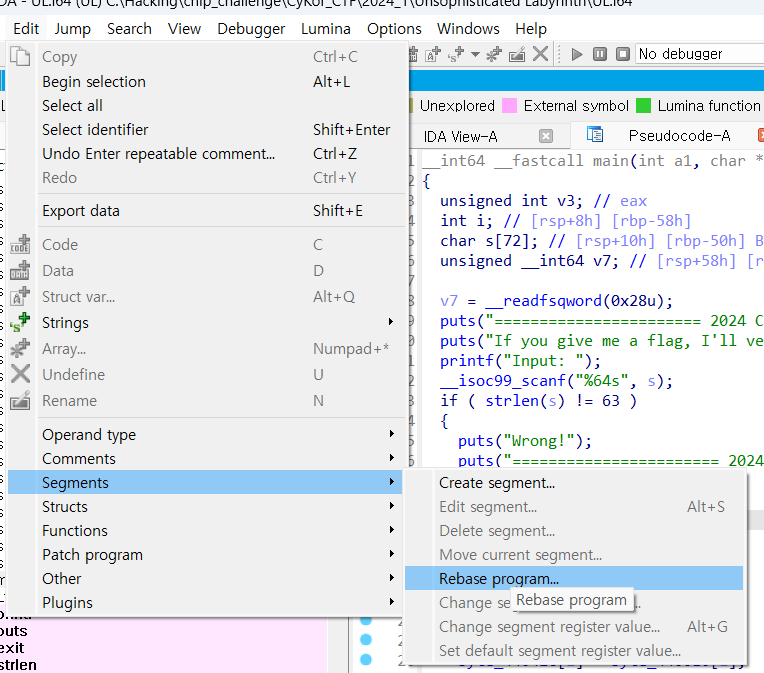
Edit - Segments - Rebase program 을 클릭하면
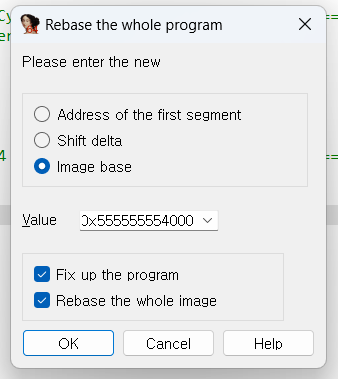
이렇게 Base를 조정할 수 있습니다. gdb와 IDA를 동시에 켜 놓고 분석할 때가 많기 때문에 gdb에서 vmmap 명령어로 ImageBase를 확인한 뒤에 해당 ImageBase로 Rebase를 해주면 IDA와 gdb에서 보이는 주소를 동기화시킬 수 있습니다. 일반적으로 gdb에서 ImageBase는 0x555555554000 이기 때문에, 0x555555554000으로 주로 설정해 둡니다. 하지만 반드시 이런 것은 아니니 주의가 필요합니다.
꼭 gdb가 아니더라도 디버거와 정적 분석 툴을 동시에 켜 둔 상태로 분석을 자주 하기 때문에, 이런 경우에는 정적 분석 툴(IDA)의 Image Base를 rebase하여 디버거의 Image Base와 동기화 시키는 것이 일반적입니다.
바이너리 명령어 패치하기
IDA에서 제공하는 강력한 기능 중 하나는 패치 기능입니다. 바이너리 패치(patch)는 바이너리에 있는 내용을 바꾸는 기능입니다
디컴파일된 코드 레벨에서 수정하는 것은 불가능 하며 최대 어셈블리 단위에서만 패치가 가능합니다.
IDA view에서 패치를 가하고 싶은 주소에 커서를 위치시킨 뒤에
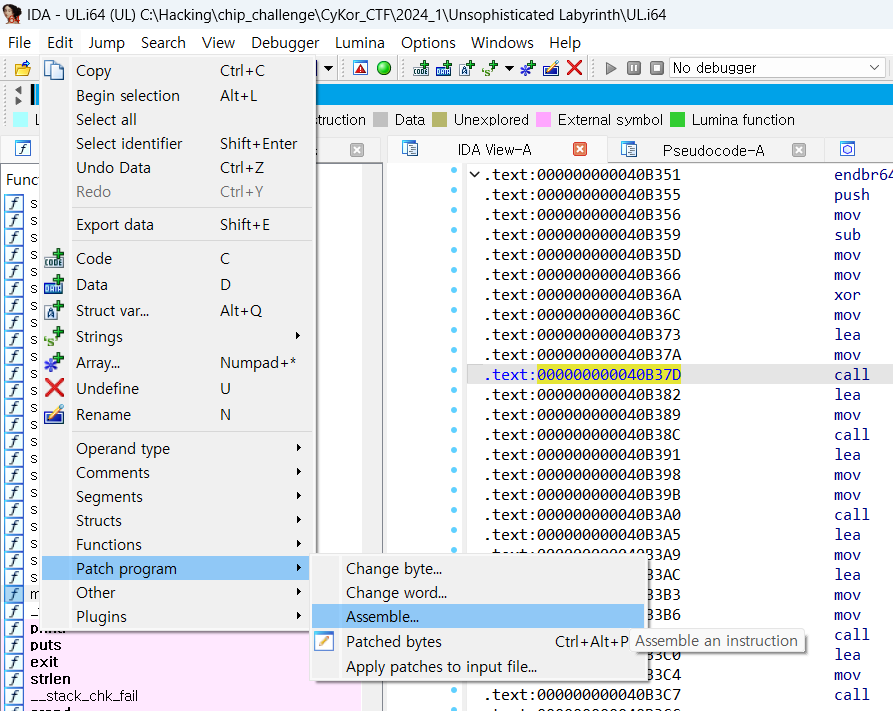
Edit - Patch program 에서 Change byte 혹은 Assemble 기능으로 주로 패치합니다. change word는 잘 안 쓰게 되더라구요.
patched bytes는 패치 내역을 보여주는 subview를 엽니다.
Apply patched to input file…의 경우에는 패치한 것을 실제 바이너리에 반영합니다. 이 기능을 사용하기 전까지는 .idb 형식의 아이다 데이터베이스에만 저장해 두다가 저 기능을 사용했을 시에 실제 바이너리에 반영됩니다. 저 기능을 사용하기 전까지는 실제 바이너리를 실행해도 패치가 적용되지 않습니다.
구조체 만들기
사용자 레벨에서 정의된 구조체는 컴파일 하면 해당 구조체 정보는 사라집니다. 대신 IDA에서는 주소 기반으로 구조체 멤버에 접근하는 것을 보실 수 있습니다(어셈블리어가 사용하는 방식). 분석하다가 이거는 구조체다 싶은거는 정의를 해두시면 편합니다.
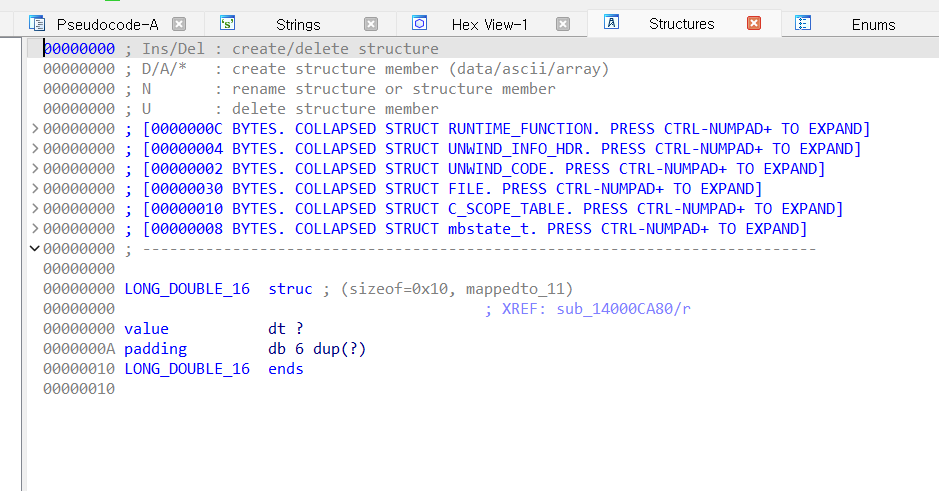
이렇게 structure subview에 들어온 모습입니다. 여기서 Insert키를 누르면 구조체를 생성할 수 있습니다.
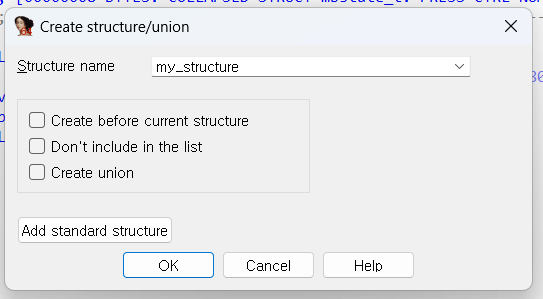
구조체 이름 넣어주시고 OK 누르면 구조체가 생성됩니다.

구조체 멤버를 추가할려면 ends 부분을 클릭하고 d를 눌러주시면 새로운 멤버 변수를 추가할 수 있습니다. 멤버 변수의 이름은 n으로 rename이 가능하며, 자료형은 아래에서 소개할 y를 눌러도 되고, 단순히 크기만 바꾸고 싶으면 d로도 가능합니다.

이런 식으로 구조체를 선언할 수 있습니다.
그 외에 Local types에서 구조체를 정의하는 방법도 있습니다.
Local types subview에서 Insert 키를 누르면
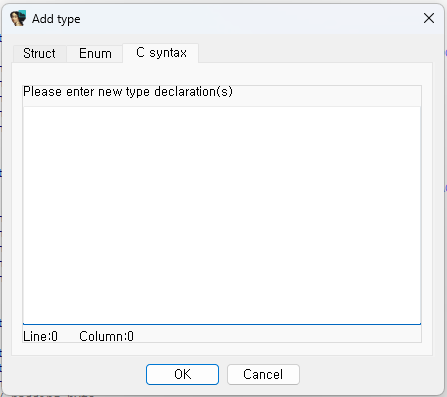
위와 같은 창을 볼 수 있습니다. Struct 창에서는 아까처럼 구조체를 추가할 수 있고, C syntax 창에 들어가면 C style로 코딩하여 구조체를 한 번에 설정할 수도 있습니다.
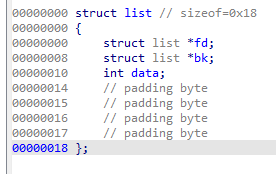
이런 식으로 간단하게 연결리스트 구조체를 작성해 보았습니다.
개인적으로는 구조체들을 추가해 둔 채로, Local types subview를 pseudocode subview와 동시에 틀어 놓고 사용하는 것을 좋아합니다(다른 고수가 이렇게 쓰길래 따라해보니 매우 편하더라). (Structure에서 구조체를 추가하여도 Local types에 표시됩니다)
자료형 재설정 및 calling convention 재설정
y : 변수 자료형 재설정 및 함수 calling convention 재설정.
일반적으로 IDA가 알아서 변수들 및 함수들의 type을 잘 설정하여 주지만 그러지 못할 때도 상당히 빈번하게 발생합니다. 특히 유저 레벨에서 선언된 구조체는 캐치하지 못하고, 배열도 종종 캐스팅을 못하는 경우가 잦기 때문에 예를 들어 int형 배열의 경우 arr[i] 형태로 이쁘게 표기가 안되고 (arr + i * 4) 이런 식으로 표기가 되는 경우를 자주 볼 수 있죠. 이런 것들은 뭐, 저는 익숙해져서 그냥 볼 때도 많은데 보기 껄끄러운 경우에 y로 array로 자료형을 재설정해주면 이쁘게 배열 형태로 잘 나오는 것을 볼 수 있습니다. 구조체도 위에서 설명한 것처럼 구조체를 정의해 주시고 y로 자료형을 정의해둔 구조체로 설정하시면 됩니다.
함수 calling convention 재설정하는 경우가 일반적으로는 잘 없기는 한데, C/C++이 아닌 타 언어로 작성된 바이너리의 경우에 IDA hexray는 결국 C/C++ 기반으로 pseudocode를 생성하기에 C/C++에서 사용하지 않는 calling convention을 캐치 못할 때가 종종 있습니다. 함수 클릭해서 y 누르면 calling convention을 재설정할 수 있고, __usercall 키워드를 이용해 calling convention을 사용자가 정의할 수도 있습니다. (근데 보통 plugin 잘 찾아보면 자동화 시켜주는 plugin 있긴 하더라)
부가적인 기능들
이 정도만 알아도 많은 것들을 할 수 있습니다. 그래도 설명하지 못한 정말 수 없이 많은 기능들이 존재합니다. 몇 가지 부가적인 기능들을 아래에 적어 놓겠습니다.
p : IDA view에서 작동하며, 커서가 가리키는 곳을 함수로 해석하기. 커서가 기리키는 곳이 함수가 아니면 실패할 수도 있습니다.
u : IDA view에서 커서가 어셈블리 명령어를 가리키고 있을 때 작동하며 커서가 가리키는 곳부터 어셈블리 해석한 것을 해제합니다. 눌러보면 raw data 형식으로 표기될 겁니다.
c : IDA view에서 작동하며, 커서가 가리키는 곳부터 디스어셈블을 시도합니다. 커서가 가리키는 곳의 데이터들이 어셈블리 명령어가 아닐 경우 실패할 수 있습니다.
위 기능들이 어디다가 필요한가… 싶지만 IDA가 함수의 시작 주소나 instruction의 시작 주소를 잘못 짚을 가능성이 존재합니다. 이런 경우에는 잘못된 주소에서부터 disassmble을 시도하기 때문에 잘못 해석된 어셈블리를 u로 풀어주고 올바른 함수 시작 위치에서 c , p를 입력하여 올바른 위치에서 어셈블리 및 함수 선언을 해 주어야 합니다. 난독화되지 않은 일반적인 바이너리에서는 보기 어려운 케이스이기는 합니다.
d : IDA view에서 커서가 raw data 형식을 가리키고 있을 때 작동하며 double의 약어 답게 해당 데이터를 해석하는 단위를 2배 늘립니다. byte(1byte), word(2byte), dword(4byte), qword(8byte) 형식으로 바꿀 수 있습니다.

위는 기본 1byte 데이터입니다. 여기서 d 를 누르면
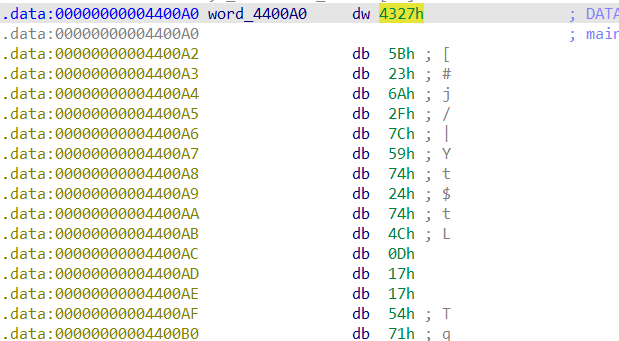
이렇게 2byte로 해석합니다. little endian인 것은 주의해 주세요.
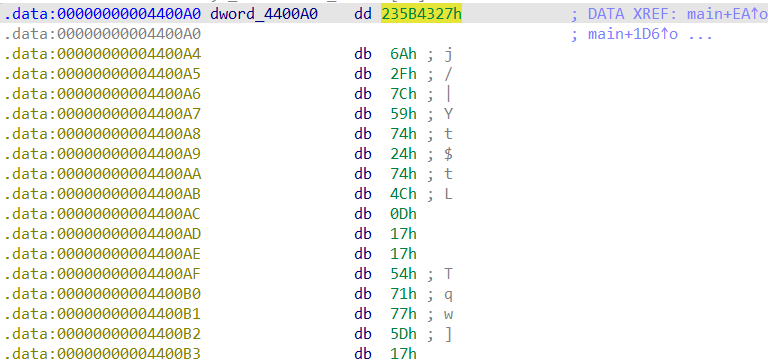
한번 더 누르면 위의 사진처럼 4byte로 해석
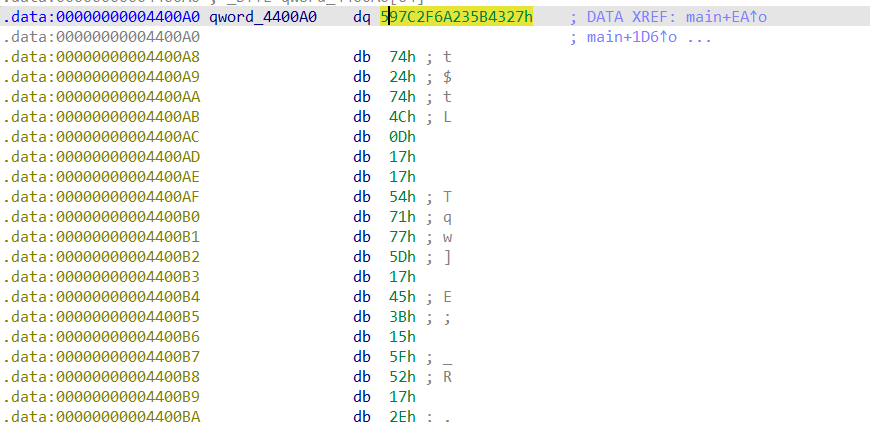
한 번 더 누르면 이렇게 8byte로 해석합니다.
이렇게 자료형을 바꾸는 기능은 자주 유용합니다. 특히 주소값이 들어 있는 포인터 변수를 1byte로 해석한 경우를 종종 볼 수 있는데 d를 4번 눌러서 qword로 바꿔주면 그 값이 유의미한 주소 값일 경우 더블 클릭하면 해당 주소의 IDA view로 이동할 수 있는 링크가 생성됩니다. (사실 y 써도 됨)
h : 데이터를 16진수로 해석합니다.

이 63이라는 숫자를 16진수로 바꿔 표현할 수 있습니다.

이런 식으로 바뀝니다. h 한 번 더 누르면 10진수로 복구 됩니다.
데이터가 10진수에서는 무슨 의미의 데이터인지 잘 모르겠지만, 16진수에서는 특별한 의미를 지녔을 수도 있습니다. 때때로 유용하게 사용되는 기능으로 생각됩니다.
g : 원하는 메모리 주소로 이동합니다. IDA view 혹은 Pseudocode subview에서 g 단축키를 누른 뒤 이동하고 싶은 주소를 입력하면 해당 주소로 이동할 수 있습니다.
alt+L : select 모드로 전환합니다.
선택하고 싶은 시작 지점에 커서를 위치시킨 뒤 alt+L 을 누르고 선택하고 싶은 끝 지점을 클릭하면 선택하고 싶은 시작 지점 ~ 끝 지점까지 한 번에 선택할 수 있습니다.
수동으로 드래그하기 어려운 매우 방대한 데이터를 모두 선택하고 싶을 때 매우 유용한 기능입니다. select 모드를 풀고 싶으면 alt+L을 한 번 더 누르면 됩니다.
캡쳐해보려고 했는데 캡쳐하니깐 마우스 커서가 사라져서..ㅋㅋ 나중에 한 번 시도해 보세요 ㅎㅎ
\ : 역슬래쉬를 쓰면 pseudocode 화면에서 표시되던 자료형이 사라지게 됩니다.
기존에 표시되던 자료형이 \를 누르게 되면
이렇게 멀끔히 사라지게 됩니다. 취향껏 사용하시면 되겠습니다.
r : 본래 기능의 명칭은 read-only 뭐시기 저시기 였던 것 같은데… 주로 숫자로 표기된 값을 ascii encoding된 값으로 보고 싶을 때 자주 사용합니다.

위 예시를 보면 strrchr 함수면 인자가 char형이니 ascii 입장에서 유의미한 값입니다. 이런 거를 ascii 문자로 바로 보고프면 47 클릭해서 r 눌러보면 변환 가능합니다.

원래대로 복구할려면 h 누르면 해결됩니다.
길이가 1byte를 초과하는 값들도 가능합니다. 다만, 이 경우에는 리틀엔디안으로 해석하지 않기 때문에 byte-order에 각별한 주의가 필요합니다.

저 0x4956과 0x5441은 딱 봐도 printable한 ASCII 값이죠??
해당 값들은 Little-Endian으로 저장되기 때문에 0x56 0x49 순으로 저장되고, 0x41 0x54 순으로 저장됩니다.
그러면 ascii string으로 변환하게 되면 “VI”, “AT”가 되죠??
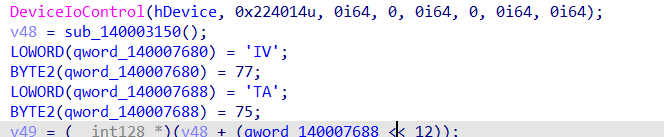
r 기능을 쓰면 이렇게 byte order가 반대로 나오기 때문에 각별한 주의가 필요합니다.
IDA 기능 사용 예시 (rename, 주석, 자료형 변경, 구조체 작성)
위 문제를 해결하는 과정에서 idb를 정리하는 것의 효과를 보여주기에 적합하다 생각하여 해당 내용을 추가합니다.
자료형 및 구조체를 잘 설정하였을 때 볼 수 있는 효과 위주로 보여드리려고 합니다. 먼저 아무런 가공을 거치지 않은 상태의 IDA 화면을 보여드린 후, 정리가 완료된 IDA 화면을 보여드리면서 비교해보겠습니다.
처음 볼 것은 허프만 압축 알고리즘 중 파일에 존재하는 값들의 빈도수를 기록하는 함수입니다.
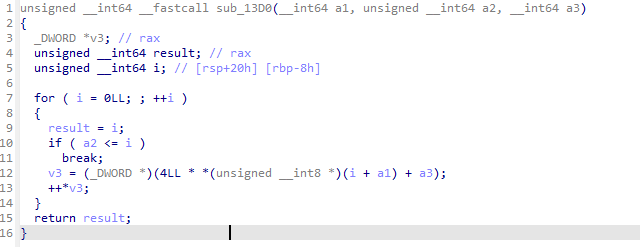
간단한 함수이기 때문에 아무런 가공이 없는 상태에서도 해석하는 것에 크게 어려움은 없습니다.
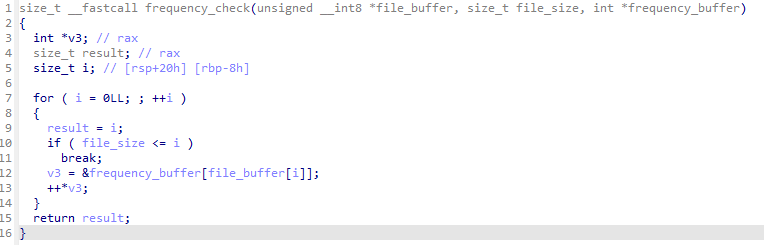
가공을 거치면 복잡한 포인터 형식으로 표현되던 것들도 이쁘게 배열로 표시되는 것을 확인할 수 있습니다.
다음으로 볼 것은 허프만 압축 알고리즘에서 트리를 형성하는 알고리즘에 해당하는 함수이며, 기존의 압축 알고리즘에서 살짝 변형되어 이진 트리가 아닌 random 값을 뽑고 그 랜덤값에 해당하는 진수의 트리를 생성하는 함수입니다.
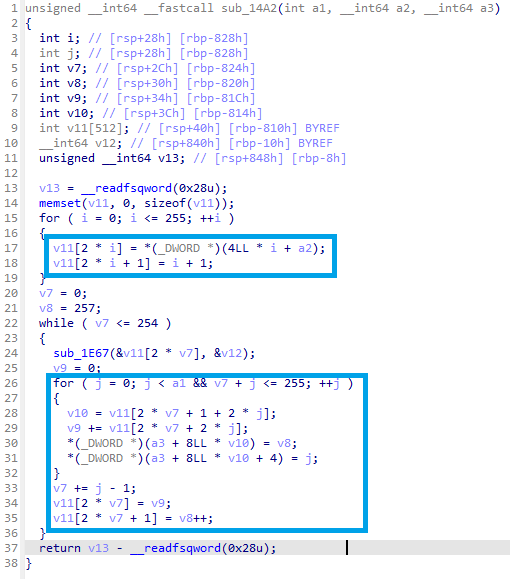
아무런 가공을 거치지 않은 상태입니다. 표시한 부분이 어떻게 바뀌는 지 유의하여 봐주세요!
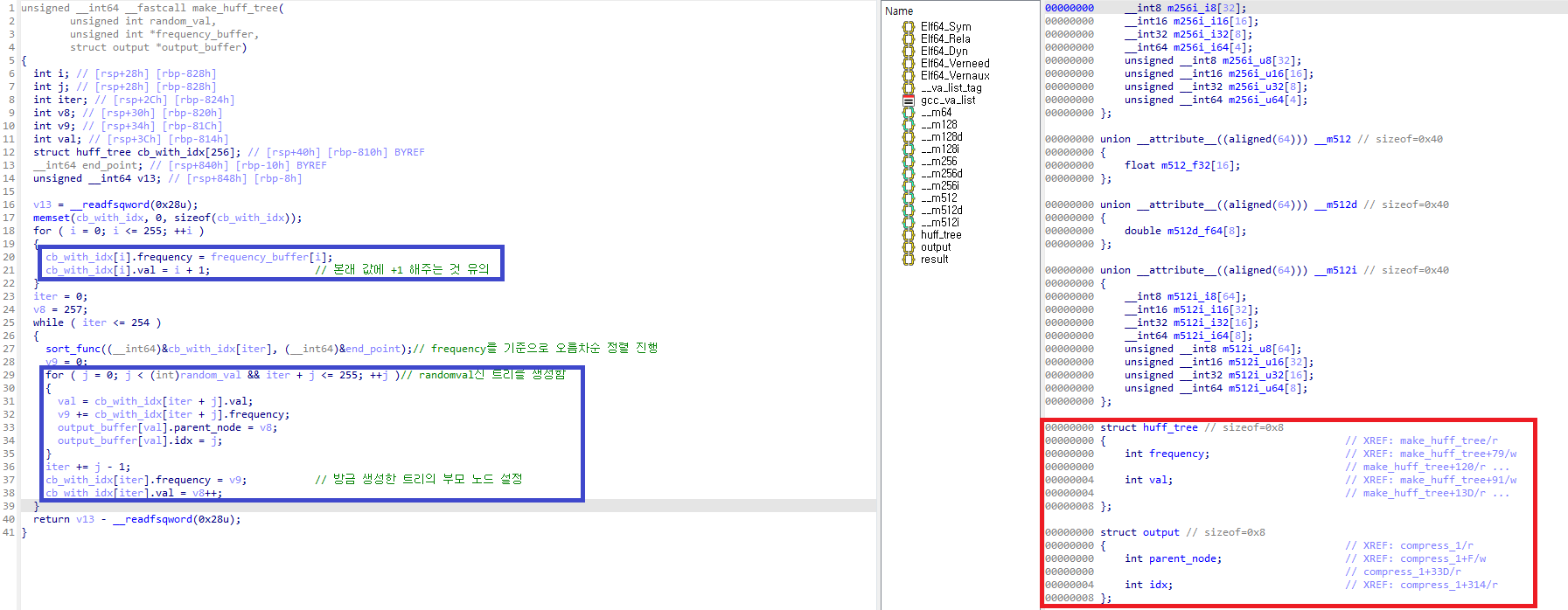
가공을 거치면 굉장히 보기 편하게 바뀝니다. (작아서 잘 안보이면 더블클릭하면 확대된 사진을 볼 수 있습니다)
구조체를 잘 설정하면 정말 편하게 볼 수 있습니다. 특히나 위에서 트리 같은 구현체들은 구조체 등을 잘 설정하지 않고 가공되지 않은 화면에서처럼 단순히 주소 기반으로만 변수 및 구조체들에 접근하는 것을 해석하는 것은 굉장히 어렵습니다. 구조체 적극적으로 이용해 주시면 좋겠습니다.
이번에도 구조체 활용 예시입니다.

표시한 부분에서 v21 변수를 살펴봅시다.

본래 IDA에서 __int64 v21; type으로 선언해 둔 변수입니다. 파란색 표시한 부분에서 v21의 활용을 살펴보면 (_DWORD)v21, SHIDWORD(v21), (int)v21 과 같은 표현으로 상위 4byte 및 하위 4byte만 활용하고 있습니다. 이런 상태에서는 해당 변수를 보기가 상당히 불편합니다.
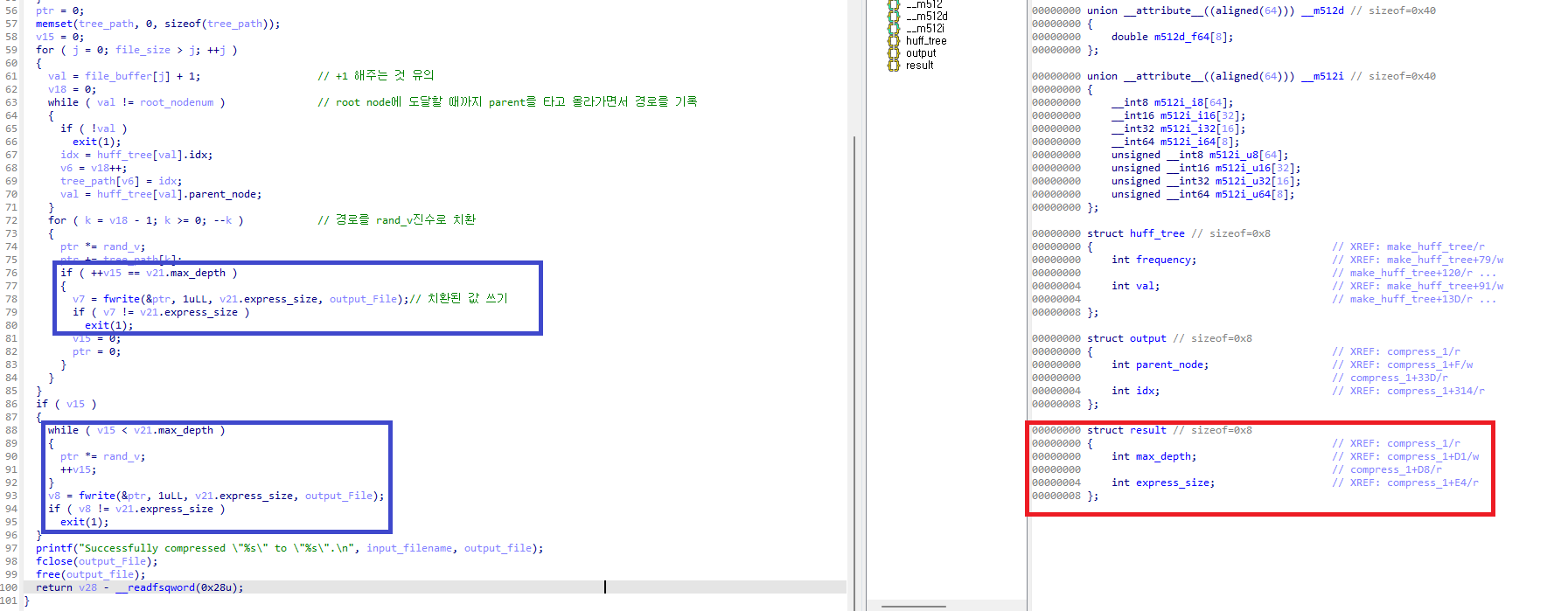
구조체 선언으로 이러한 부분들을 쉽게 해결할 수 있습니다. (작아서 잘 안보이면 더블클릭하면 확대된 사진을 볼 수 있습니다)
마지막으로 압축 과정을 총괄하는 함수 전체에 대해서 정리 전후 캡처본을 올려드리겠습니다.

아무런 가공을 거치지 않은 상태

예쁘게 정리한 모습입니다.
물론 IDA를 위처럼 꾸미는 것이 분석의 목표는 아닙니다만, 분석을 진행하면서 필요한 정보들을 기록하고 소스에 반영할 수 있도록 IDA는 많은 기능들을 제공하고 있습니다.
→ 분석에 많은 도움이 된다!