
Katanaverse 0.0
상위 포스트 - bi0s CTF 2024
이름: 정지민
닉네임: mini_chip
소속: 고려대학교 사이버국방학과
분야: Reversing
체감 난이도(1~10): 8
flag: bi0sCTF{QuBitJugglr}
문제 파일
풀이 과정

c 바이너리이고, 조건을 만족하는 input을 구해야 합니다.
main의 첫 부분에 func_0 함수를 호출하는데
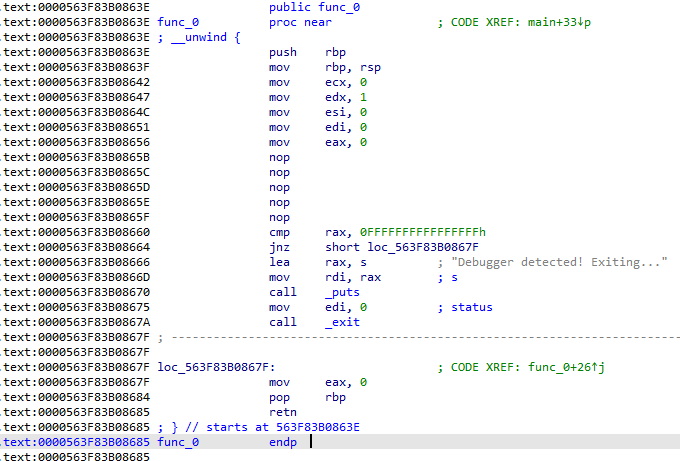
문제 풀면서 패치 했기 때문에 지금은 nop 명령어로 도배 되어 있지만, 본래 ptrace 호출이 존재했습니다. 디버깅 중이라고 판단될 경우 대놓고 exit() 호출하였기 때문에 어렵지 않게 안티 디버깅 로직을 파악할 수 있습니다.
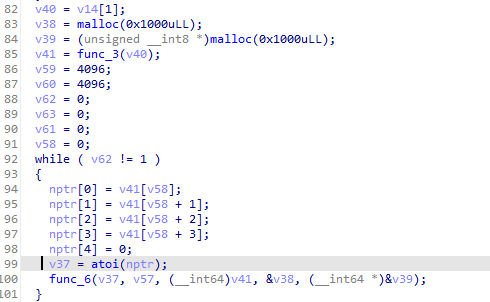
그 다음은 katanaverse의 1단계에 해당한다고 볼 수 있는 지옥의 func_6()입니다.
stack과 data영역이 2차례 malloc으로 구현되어 있고, func_3() 에서는 dump.dmp파일을 open해서 읽어옵니다.
그리고 while loop를 돌면서 dump.dmp 파일 파싱 및 그에 맞는 동작을 수행합니다.
func_6 을 까보면 44가지의 case가 있는 switch case문으로 구현되어 있습니다.
descriptor 짤 때 힘들어서 죽는 줄 알았습니다.
분기가 존재하는데, jne jmp je 가 존재하며 어디로 jmp하는지는 정적으로도 알 수 있기 때문에 일단 descriptor에서는 pc가 증가하는 순서대로 그대로 어셈을 뽑았습니다.

근데 뽑다가 보면 에러가 펑 터집니다. 여기서 1차 멘탈 펑 했습니다.
멘탈 다시 부여잡고 분석해 보니, 제 desciptor 코드의 문제는 아니었고 dump.dmp파일에 파싱이 안되는 더미 코드가 있을 거라 추측되었고, 실제 실행하는 부분만 골라서 파싱할 수 있도록 jmp문이 나오면 branch 여부를 입력하도록 해서 실제 실행 흐름과 동기화 하여 어셈을 뽑을 수 있도록 descriptor를 수정하였습니다.
descriptor.py
import base64
f = open("dump.dmp", "rb")
global pc
pc = 0
white_list = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/"
def parse_code():
global pc
print("%d:"%pc, end=" ")
f.seek(pc, 0)
opcode = int(f.read(4).decode())
pc += 4
if opcode == 1200:
dst = int(f.read(3).decode()) - 700
src = int(f.read(3).decode()) - 700
print("mov reg[%d], reg[%d]"%(dst, src))
print("mo reg[%d], 0"%(src))
pc += 6
elif opcode == 1201:
dst = int(f.read(3).decode()) - 700
src = int(f.read(1).decode())
print("mov reg[%d], %d"%(dst, src))
pc += 4
elif opcode == 1202:
dst = int(f.read(3).decode()) - 700
src = int(f.read(3).decode()) - 700
print("mov reg[%d], reg[%d]"%(dst, src))
pc += 6
elif opcode == 1203:
dst = int(f.read(3).decode()) - 700
src = int(f.read(1).decode())
print("add reg[%d], %d"%(dst, src))
pc += 4
elif opcode == 1204:
dst = int(f.read(3).decode()) - 700
src = int(f.read(3).decode()) - 700
print("add reg[%d], reg[%d]"%(dst, src))
pc += 6
elif opcode == 1205:
dst = int(f.read(3).decode()) - 700
src = int(f.read(1).decode())
print("sub reg[%d], %d"%(dst, src))
pc += 4
elif opcode == 1206:
dst = int(f.read(3).decode()) - 700
src = int(f.read(3).decode()) - 700
print("sub reg[%d], reg[%d]"%(dst, src))
pc += 6
elif opcode == 1207:
dst = int(f.read(3).decode()) - 700
src = int(f.read(1).decode())
print("xor reg[%d], reg[%d]"%(dst, src))
pc += 4
elif opcode == 1208:
dst = int(f.read(3).decode()) - 700
src = int(f.read(3).decode()) - 700
print("xor reg[%d], reg[%d]"%(dst, src))
pc += 6
elif opcode == 1209:
dst = int(f.read(3).decode()) - 700
src = int(f.read(1).decode())
print("div reg[%d], reg[%d]"%(dst, src))
pc += 4
elif opcode == 1210:
dst = int(f.read(3).decode()) - 700
src = int(f.read(3).decode()) - 700
print("div reg[%d], reg[%d]"%(dst, src))
pc += 6
elif opcode == 1211:
dst = int(f.read(3).decode()) - 700
src = int(f.read(1).decode())
print("mul reg[%d], reg[%d]"%(dst, src))
pc += 4
elif opcode == 1212:
dst = int(f.read(3).decode()) - 700
src = int(f.read(3).decode()) - 700
print("mul reg[%d], reg[%d]"%(dst, src))
pc += 6
elif opcode == 1213:
dst = int(f.read(3).decode()) - 700
print("pop reg[%d]"%(dst))
pc += 3
elif opcode == 1214:
dst = int(f.read(3).decode()) - 700
print("push reg[%d]"%(dst))
pc += 3
elif opcode == 1215:
dst = int(f.read(3).decode()) - 700
src = int(f.read(1).decode())
print("mov reg[%d], data[reg[8]+%d]"%(dst, src))
pc += 4
elif opcode == 1216:
dst = int(f.read(3).decode()) - 700
print("mov data[reg[8]], reg[%d]"%(dst))
print("inc reg[8]")
pc += 3
elif opcode == 1217:
src = int.from_bytes(f.read(1), byteorder="little")
pc += (1+src)
src = int.from_bytes(f.read(src), byteorder="little")
print("call %x"%(src))
elif opcode == 1218:
dst = int(f.read(3).decode()) - 700
print("inc reg[%d]"%(dst))
pc += 3
elif opcode == 1219:
dst = int(f.read(3).decode()) - 700
print("dec reg[%d]"%(dst))
pc += 3
elif opcode == 1220:
dst = int(f.read(3).decode()) - 700
src = int(f.read(1).decode())
print("mov reg[%d], data[reg[8]+%d]"%(dst, src))
print("mov data[reg[8]+%d], 0"%(src))
pc += 4
elif opcode == 1221:
dst = int(f.read(3).decode()) - 700
src = int(f.read(1).decode())
print("sr reg[%d], %d"%(dst, src))
pc += 4
elif opcode == 1222:
dst = int(f.read(3).decode()) - 700
src = int(f.read(3).decode()) - 700
print("sr reg[%d], reg[%d]"%(dst, src))
pc += 6
elif opcode == 1223:
dst = int(f.read(3).decode()) - 700
src = int(f.read(1).decode())
print("sl reg[%d], %d"%(dst, src))
pc += 4
elif opcode == 1224:
dst = int(f.read(3).decode()) - 700
src = int(f.read(3).decode()) - 700
print("sl reg[%d], reg[%d]"%(dst, src))
pc += 6
elif opcode == 1225:
cnt = int.from_bytes(f.read(1), byteorder="little")
operand = f.read(cnt).decode()
pc += (1 + cnt)
print("puts(%s)"%operand)
elif opcode == 1226:
dst = int(f.read(3).decode()) - 700
print("print(reg[%d])"%dst)
pc += 3
elif opcode == 1227:
dst = int(f.read(3).decode()) - 700
src = int.from_bytes(f.read(1), byteorder="little")
if src == 36:
src = 10
else:
src = int(chr(src))
print("mov reg[%d], stack[sp+(%d)]"%(dst, src))
pc += 4
elif opcode == 1228:
dst = int.from_bytes(f.read(1), byteorder="little")
print("je %d"%(pc+dst-4))
a = input("jmp or not? [y/n]")
if a == 'n':
pc += 1
else:
pc = pc+dst-4
elif opcode == 1229:
dst = int.from_bytes(f.read(1), byteorder="little")
print("jne %d"%(pc+dst-4))
a = input("jmp or not? [y/n]")
if a == 'n':
pc += 1
else:
pc = pc+dst-4
elif opcode == 1230:
dst = int.from_bytes(f.read(1), byteorder="little")
print("jmp %d"%(pc+dst-4))
a = input("jmp or not? [y/n]")
if a == 'n':
pc += 1
else:
pc = pc+dst
elif opcode == 1231:
sw = int.from_bytes(f.read(1), byteorder="little")
pc += 1
print("case 1231.. pass..")
if sw == 105:
dst = int(f.read(3).decode())
pc += 3
print("dst: %d"%dst)
elif sw == 115:
print("fgets(100), data에 bios{flag}의 flag만 base64 encoding해서 저장. reg[0] = len(after encode)")
elif opcode == 1232:
dst = int(f.read(3).decode()) - 700
try:
src = int(f.read(1).decode(encoding = "ascii"))
except:
src = int.from_bytes(f.read(1), byteorder="little")
print("cmp reg[%d], %d"%(dst, src))
pc += 4
elif opcode == 1233:
dst = int(f.read(3).decode()) - 700
src = int(f.read(3).decode()) - 700
print("cmp reg[%d], reg[%d]"%(dst, src))
pc += 6
elif opcode == 1234:
print("END")
pc += 0
return 0
elif opcode == 1235:
dst = int(f.read(3).decode()) - 700
src = int(f.read(1).decode())
print("and reg[%d], %d"%(dst, src))
pc += 4
elif opcode == 1236:
dst = int(f.read(3).decode()) - 700
src = int(f.read(3).decode()) - 700
print("and reg[%d], reg[%d]"%(dst, src))
pc += 6
elif opcode == 1237:
dst = int(f.read(3).decode()) - 700
src = int(f.read(1).decode())
print("or reg[%d], %d"%(dst, src))
pc += 4
elif opcode == 1238:
dst = int(f.read(3).decode()) - 700
src = int(f.read(3).decode()) - 700
print("or reg[%d], reg[%d]"%(dst, src))
pc += 6
elif opcode == 1239:
dst = int.from_bytes(f.read(1), byteorder="little")
print("je %d"%(pc-dst-4))
a = input("jmp or not? [y/n]")
if a == 'n':
pc += 1
else:
pc = pc-4-dst
elif opcode == 1240:
dst = int.from_bytes(f.read(1), byteorder="little")
print("jne %d"%(pc-dst-4))
a = input("jmp or not? [y/n]")
if a == 'n':
pc += 1
else:
pc = pc-4-dst
elif opcode == 1241:
dst = int.from_bytes(f.read(1), byteorder="little")
print("jmp %d"%(pc-dst-4))
a = input("jmp or not? [y/n]")
if a == 'n':
pc += 1
else:
pc = pc-dst
elif opcode == 1242:
dst = int.from_bytes(f.read(1), byteorder="little")
print("jne %d"%dst)
a = input("jmp or not? [y/n]")
if a == 'n':
pc += 1
else:
pc = dst
elif opcode == 1243:
dst = int.from_bytes(f.read(1), byteorder="little")
print("je %d"%dst)
a = input("jmp or not? [y/n]")
if a == 'n':
pc += 1
else:
pc = dst
else:
print("invalid opcode")
return 1
flag = 1
while flag:
flag = parse_code()
뽑은 어셈대로 로직을 분석해보면 다음과 같습니다.
encoding하면서 data에 저장
r0 = len(encoded flag)
encoding된 flag를 모두 push
data뒤에서 부터 1byte를 8개의 bit로 쪼개서 push
encoded len만큼 반복
{
6번 반복 loop [
0 ^ 8
1 ^ 9
2 ^ 10
1 ^ 8
0 ^ 9
2 ^ 9
1 ^ 10
0 ^ 2 ^ 9
위 연산값들 data에 저장
pop
]
반복 이후 2번 pop해서 총 8번 pop
} (이걸 총 len-1만큼 반복해가며 data에 저장)
그 다음은 문제의 2단계에 해당하는 부분입니다. VM 해석도 절대 쉬운 것이 아니었는데… 아직 끝나지 않았습니다.

이것 아래도 로직이 추가로 존재합니다만, 굳이 분석할 필요는 없습니다.
여기서 Wrong Input 검증을 통과하게 되면, 이후에는 브포로 해결하는 것이 인텐으로 보입니다.
일단 srand시드 같은 경우는, flag 첫 8byte로 결정을 하게 되는데, flag format은 bi0sCTF{...} 로 고정되어 있기 때문에 시드 또한 고정되어 있습니다. rand() 값은 당연히 예측 가능한 값들이 되는 것이고…
마지막 검증을 보면 for (ii ≤ 4) 로 총 5번 검증을 하게 되는데.. 이게 1byte에 대한 검증 값입니다. 5번의 검증이 비트에 관한 검증이기 때문에 8bit를 검증하는 5개의 식이 있게 되는 것이죠.
이렇게 되면 당연히 중복 flag가 생길 수 밖에 없습니다.
위 캡처 하단의 로직은 중복 flag를 차단하기 위한 유사 hash 처리로 보여서 분석 대상에서 제외 했습니다.
주목해야 할 점은 flag 관련 연산 로직이 (byte)flag[i]와 (byte)flag[i+1]를 가지고 한 결과로 output[i]가 결정된다는 점입니다. 게다가 초기 flag가 bi0sCTF{ 로 이미 알고 있는 값이니 사실상 1 byte brute-force로 문제를 해결할 수 있습니다. 다만, 중복 플래그의 존재성 때문에 DFS로 구현해야 합니다.
중복 플래그를 뽑다 보면…. 너무 많은 플래그들이 쏟아져 나옵니다. 더군다나 다 뽑는 데도 상당한 시간이 소요되었습니다. 그래서 이를 어느 정도 최적화가 필요해 보였습니다.
VM 관련 로직에서 base64 encoding을 진행합니다. 그렇기 때문에 당연히 1바 브포 때릴 때도 encoding된 결과값인 [A-Za-z0-9+/] 안에서만 브포를 때렸습니다.
여기서 base64 encoding을 디코딩한 결과가 ascii printable이라는 점을 알아야 합니다.
그렇기 때문에 1-byte brute force를 진행하면서 플래그를 구한 곳 까지 디코딩했을 시 printable하지 않거나 decoding 과정 중 오류가 발생하면 해당 케이스에서 더 깊숙히 들어가지 않도록 쳐내는 방식으로 최적화를 했습니다. 당연히 디코딩 단위는 4의 배수로 진행하였습니다.
exploit code
import base64
from ctypes import *
from string import printable
libc = CDLL('/lib/x86_64-linux-gnu/libc.so.6')
test = input("flag:")
encoded_string = base64.b64encode(test.encode()).decode()
dst = "bi0sCTF{" + encoded_string + "}"
print(dst)
byte_list = [ord(elem) for elem in dst]
print(byte_list)
bit_list = []
for i in byte_list:
tmp = i
tmp_list = []
for j in range(8):
tmp_list.append(tmp & 1)
tmp >>= 1
for j in range(8):
bit_list.append(tmp_list[7-j])
res_list = []
for i in range(len(dst) - 1):
for j in range(6):
res_list.append(bit_list[0] ^ bit_list[8])
res_list.append(bit_list[1] ^ bit_list[9])
res_list.append(bit_list[2] ^ bit_list[10])
res_list.append(bit_list[1] ^ bit_list[8])
res_list.append(bit_list[0] ^ bit_list[9])
res_list.append(bit_list[2] ^ bit_list[9])
res_list.append(bit_list[1] ^ bit_list[10])
res_list.append(bit_list[0] ^ bit_list[2] ^ bit_list[9])
bit_list = bit_list[1:]
bit_list = bit_list[2:]
'''
v70 = []
for i in range(16):
tmp = 0
for j in range(8):
tmp += 2**(7-j) * res_list[8*i+j]
v70.append(tmp)
print(v70)
'''
global cmp_table
cmp_table0 = [
0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0x01, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x01, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x01, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
0x01, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x00, 0x00,
0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0x01, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x01, 0x00,
0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x01, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x01, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x01, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0x01, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x00, 0x00,
0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x01, 0x00,
0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x01, 0x00,
0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x01, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
0x01, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x00, 0x00,
0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x01, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x01, 0x00,
0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x01, 0x00,
0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,
0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00
]
cmp_table = []
for i in range(120):
tmp = cmp_table0[4*i] + cmp_table0[4*i+1] + cmp_table0[4*i+2] + cmp_table0[4*i+3]
cmp_table.append(tmp)
print(cmp_table)
print(len(cmp_table))
#srand에 들어갈 seed를 계산하는 건데... 이게 "bi0sCTF{" 8글자로만 생성하는 거라 매번 고정된 값
v20 = 0
for i in range(0, 8, 2):
print(i)
v20 += 4 * res_list[8 * i + 1] + res_list[8 * i + 3] + 2 * res_list[8 * i + 2] + 8 * res_list[8 * i]
v20 += 4 * res_list[8 * i + 13] + res_list[8 * i + 15] + 2 * res_list[8 * i + 14] + 8 * res_list[8 * i + 12]
print(v20)
#########################################################################################
#고정된 seed로 인해서 rand()값을 다 뽑아낼 수 있음. 다 뽑아서 list화시킴
global rlist
rlist = []
libc.srand(43 ^ 0x72)
for j in range(24):
rl = []
rl.append(libc.rand() % 4)
for i in range(1, 3):
while True:
while True:
tmp = libc.rand() % 4
if tmp != rl[i-1]:
break
if tmp != rl[0]:
break
rl.append(tmp)
rl.append(4)
rl.append(5)
rlist.append(rl)
'''
cnt = 0
cnt1 = 0
for m in range(0, 6 * (len(dst) - 1), 6):
print("verify", m)
for ii in range(5):
res = res_list[8*m + 8 * rlist[cnt][ii]] == res_list[8*m + 7 + 8*rlist[cnt][ii]]
if res != cmp_table[cnt1]:
print("Wrong!")
exit()
cnt1 += 1
cnt += 1
print("Correct!")
'''
def verify(flag):
global cmp_table
init_flag = "bi0sCTF{T"
for hi in range(1):
for pos in printable:
dst = flag
byte_list = [ord(elem) for elem in dst]
bit_list = []
for i in byte_list:
tmp = i
tmp_list = []
for j in range(8):
tmp_list.append(tmp & 1)
tmp >>= 1
for j in range(8):
bit_list.append(tmp_list[7-j])
res_list = []
for i in range(len(dst) - 1):
for j in range(6):
res_list.append(bit_list[0] ^ bit_list[8])
res_list.append(bit_list[1] ^ bit_list[9])
res_list.append(bit_list[2] ^ bit_list[10])
res_list.append(bit_list[1] ^ bit_list[8])
res_list.append(bit_list[0] ^ bit_list[9])
res_list.append(bit_list[2] ^ bit_list[9])
res_list.append(bit_list[1] ^ bit_list[10])
res_list.append(bit_list[0] ^ bit_list[2] ^ bit_list[9])
bit_list = bit_list[1:]
bit_list = bit_list[2:]
cnt = 0
cnt1 = 0
wf = 0
for m in range(0, 6 * (len(flag) - 1), 6):
for ii in range(5):
res = res_list[8*m + 8 * rlist[cnt][ii]] == res_list[8*m + 7 + 8*rlist[cnt][ii]]
if res != cmp_table[cnt1]:
wf = 1
break
cnt1 += 1
if wf == 1:
break
cnt += 1
if wf == 1:
return -1
else:
try:
encoded_string = flag[8:-1]
assert len(encoded_string) == 16
decoded_string = base64.b64decode(encoded_string).decode(encoding = "ascii")
res = "bi0sCTF{" + decoded_string + "}"
f.write(res + "\n")
print(encoded_string)
return 1
except:
#print("decoding error")
return 0
#DFS()
f = open("result.txt", "w")
def brute_force(init_flag):
printable = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/="
if len(init_flag) == 24:
verify(init_flag + "}")
return
for pos in printable:
dst = init_flag + pos
byte_list = [ord(elem) for elem in dst]
bit_list = []
for i in byte_list:
tmp = i
tmp_list = []
for j in range(8):
tmp_list.append(tmp & 1)
tmp >>= 1
for j in range(8):
bit_list.append(tmp_list[7-j])
res_list = []
for i in range(len(dst) - 1):
for j in range(6):
res_list.append(bit_list[0] ^ bit_list[8])
res_list.append(bit_list[1] ^ bit_list[9])
res_list.append(bit_list[2] ^ bit_list[10])
res_list.append(bit_list[1] ^ bit_list[8])
res_list.append(bit_list[0] ^ bit_list[9])
res_list.append(bit_list[2] ^ bit_list[9])
res_list.append(bit_list[1] ^ bit_list[10])
res_list.append(bit_list[0] ^ bit_list[2] ^ bit_list[9])
bit_list = bit_list[1:]
bit_list = bit_list[2:]
cnt = 0
cnt1 = 0
wf = 0
for m in range(0, 6 * (len(dst) - 1), 6):
for ii in range(5):
res = res_list[8*m + 8 * rlist[cnt][ii]] == res_list[8*m + 7 + 8*rlist[cnt][ii]]
if res != cmp_table[cnt1]:
wf = 1
break
cnt1 += 1
if wf == 1:
break
cnt += 1
if wf == 1:
continue
else:
if len(dst) >= 13:
encoded_string = dst[8:]
try:
decoded_string = base64.b64decode(encoded_string[:-(len(encoded_string) % 4)])
test = decoded_string
test.decode(encoding = "ascii")
brute_force(dst)
#print(dst)
except:
continue
else:
brute_force(dst)
brute_force("bi0sCTF{")
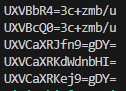
그러면 1분이 되지 않는 시간 안에 가능성 있는 flag 값을 뽑아 볼 수 있습니다.
근데 딱 보니 저 중에서 디코딩이 정상적으로 될 것 같은 놈은 4번째 놈밖에 없죠?
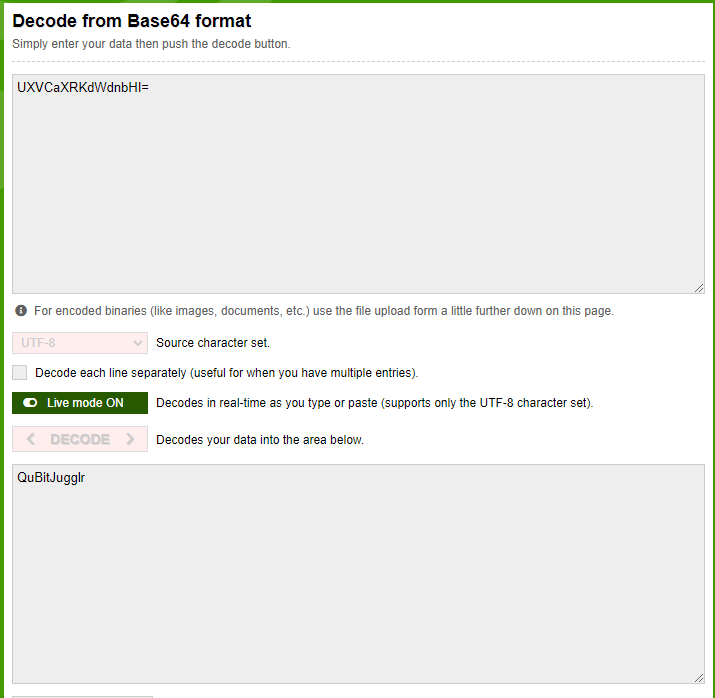
flag: bi0sCTF{QuBitJugglr}
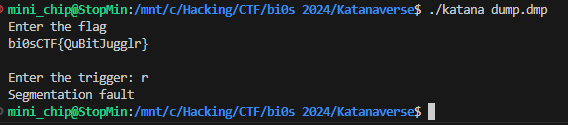
flag로 넣으면 segfault가 납니다.
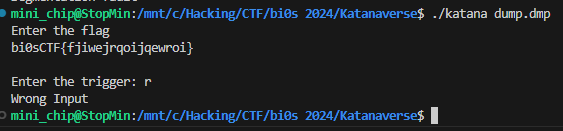
잘못 된 flag 값을 넣었을 경우에는 이렇게 Wrong Input이라고 출력해 주는데 그냥 코딩을 잘못한 것 같습니다.
이후 Katanaverse 1.0 문제에서는 문제 설명에 올바른 flag를 입력 시에 crash가 날 것이라고 설명이 추가로 생겼습니다.
기본적으로 상당한 복잡도를 가지고 있고, 분석에 많은 노동력을 요구했습니다. 그래도 리버서라면 궁뎅이라도 무거울 줄 알아야죠 껄껄껄.
최종 8솔짜리 리버싱에서는 0솔 Katanaverse 1.0을 제외하고가장 높은 배점을 가진 문제가 되었는데… 에잉 쯧.. 포기만 안 했으면 충분히 풀 수 있을 만한 문제라고 생각했건만… 이렇게 못 풀 줄은 몰랐네요.
대회 종료 후에 출제자가 인텐 풀이로 풀이한 사람이 한 명도 없다는 충격 발언을 하셨슴니다.
인텐 풀이는 Quantum Computing 이라는 데.. 뭔 지는 몰라요. 보통 양자 알고리즘이 일반 컴퓨터에서 더 효율 적인 경우가 있나…?? 양자 알고리즘 말고 다른 걸 말한건가…? 모르겠네요.
제약 조건을 너무 많이 걸어 놔서 다른 언인텐 풀이가 발생한 것 같다고 말했습니다.
실제로 제약 조건이 훨씬 널널한 문제로 Katanaverse 1.0 이 리벤지 문제로 추가되었습니다. Katanaverse 0.0 에서 인텐 풀이로 풀었다면 바로 풀 수 있는 문제였기에 모두가 언인텐 풀이로 푼 것 같다고 말한 것 같네요. 아무래도 언인텐 풀이를 예상하고 일부러 0.0, 1.0을 따로 준비한 것 같습니다.
Katanaverse 1.0 에서 최대한 최적화를 해서 브포를 진행했는데 몇 시간이 흘러도… 유의미한 플래그 후보를 단 한개도 얻지 못했습니다 ㅠㅠㅠㅠㅠ…
0.0에서는 8개의 비트에 대한 검증식이 5개가 주어졌는데, 1.0에서는 3개가 주어지는 걸로 바뀐 것이 다입니다. 그리고 플래그의 길이가 조금 더 길어졌다는 정도?
뭐 언인텐 풀이 기준으로도 Katanaverse 0.0 은 쉬운 문제는 아니었던 것 같습니다. 그래도 그렇게 어려운 것 같지는 않고… 그냥 좀 사이즈와 복잡도가 커서 어려운 문제??? 정도였네요.